Conseil scientifique - Analyse/Synthèse - janvier 2000
Segmentation et étiquetage : présentation
- Stéphane Rossignol -
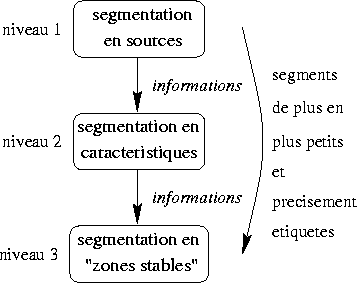
La procédure de segmentation est hiérarchique. Trois niveaux de segmentation sont définis. Les informations obtenues à un certain niveau sont propagées vers les niveaux inférieurs pour améliorer leurs performances. Les segments trouvés sont de plus en plus petits et précisément étiquetés.
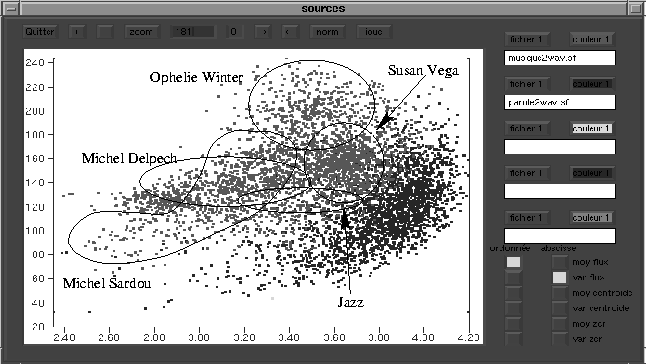
Le but du premier niveau de segmentation est de classifier le son suivant sa nature. Les deux classes considérées sont la parole et la musique. Les sons utilisés sont par exemple des bandes son de film ou des enregistrements radiophoniques.
L'analyse se décompose en deux étapes :
calculées sur des fenêtres temporelles de 30 ms. Et les fonctions d'observation sont : la moyenne et la variance des fonctions de << base >> calculées sur des segments d'une seconde.
Le pourcentage d'erreur avec les six caractéristiques est :
| apprentissage | test | validation croisée |
|
| Deux Gaussiennes | 4,0 | 3,6 | 9,3 |
| 7 plus proches voisins | 1,3 | 1,5 | 5,9 |
| Réseaux de neurones | 1,9 | 1,7 | 4,7 |
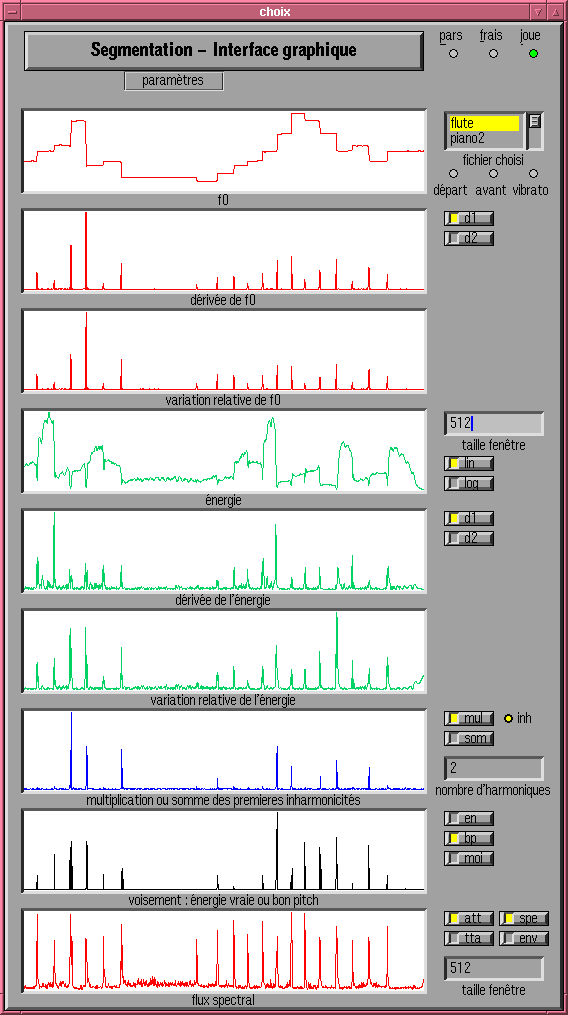
Lors du niveau de segmentation en caractéristiques, nous étiquetons des segments avec des caractéristiques du type : silence/son, voisé/non voisé, harmonique/inharmonique, présence de vibrato/absence de vibrato...
Nous avons vu que le premier niveau de segmentation répondait à cette première question :
Si le signal est de la musique, le deuxième niveau de segmentation peut commencer. Une série de questions est posée. Nous donnons un exemple ci-dessous :
Il s'agit ici de poser des marques de segmentation sur un son, dans le but d'obtenir des segments de son étiquetés qui soient manipulables (recherche dans des bases de données), transformables...
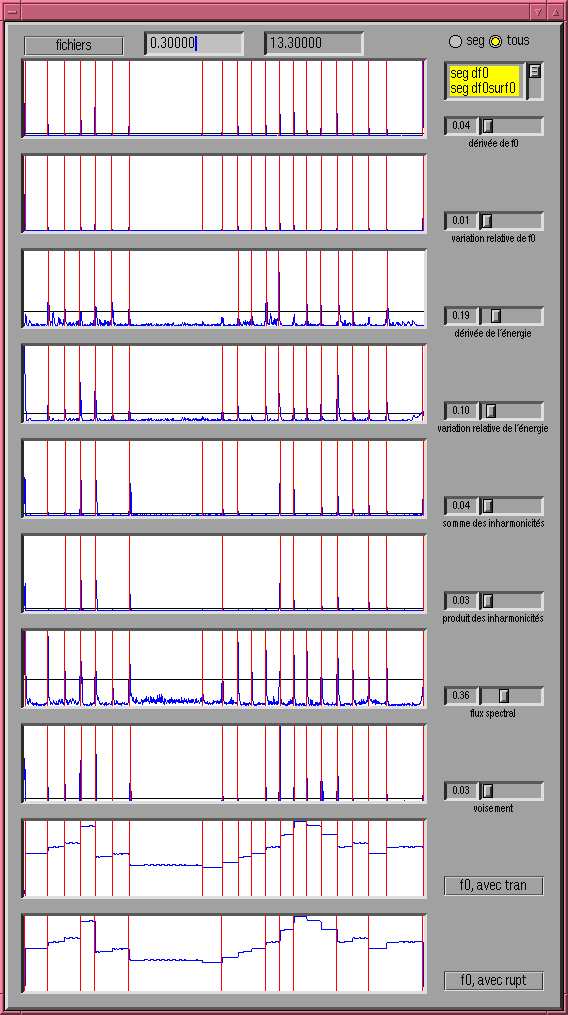
La définition de zone stable dépend du type de son considéré. Nous donnons deux exemples :
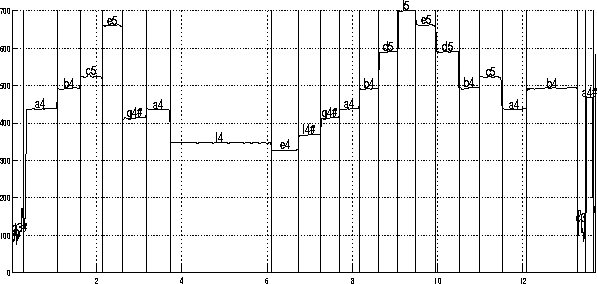
Dans la suite, nous allons considérer que le son est Harmonique, Voisé et Monophonique. Le dernier niveau est la segmentation du signal en notes .
Elle est composée de quatre étapes :
Nous espérons d'une fonction d'observation qu'elle présente des pics aussi grands et fins que possible aux moments des transitions, et que sa moyenne et sa variance soient aussi petites que possible dans les zones stables.
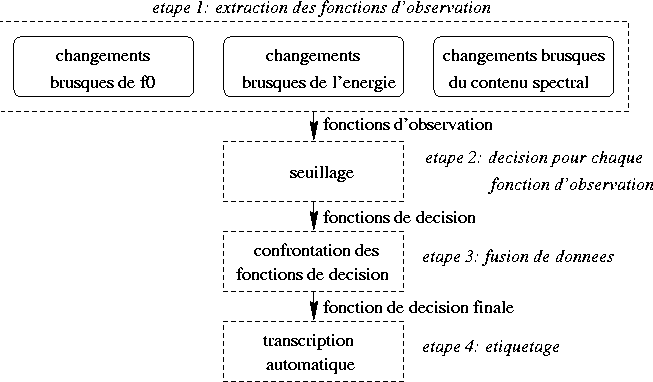
Trois types de fonctions d'observation sont utilisés pour mettre en évidence les transitions :
Des méthodes de seuillage statistiques, venant notamment du traitement des images, sont utilisées.
Par exemple, nous utilisons la méthode des 3 ![]() .
Nous décidons que tous les pics supérieurs à 3
.
Nous décidons que tous les pics supérieurs à 3 ![]() ,
où
,
où ![]() est l'écart-type du bruit (observé dans les zones stables),
sont des pics ne correspondant pas à du bruit (correspondant donc
à des transitions). Il y a une justification théorique à
ce seuil, avec le seuil universel défini par Donoho. Ce seuil est
égal à s =
est l'écart-type du bruit (observé dans les zones stables),
sont des pics ne correspondant pas à du bruit (correspondant donc
à des transitions). Il y a une justification théorique à
ce seuil, avec le seuil universel défini par Donoho. Ce seuil est
égal à s = ![]() ,
où M est la taille du signal en nombre d'échantillons. Donoho
prouve que quand M tend vers l'infini la probabilité qu'un échantillon
de bruit dépasse s tend vers 0. Et pour M de l'ordre de 1000
s est très proche de 3 (3,72). Le problème est de
parvenir à déterminer
,
où M est la taille du signal en nombre d'échantillons. Donoho
prouve que quand M tend vers l'infini la probabilité qu'un échantillon
de bruit dépasse s tend vers 0. Et pour M de l'ordre de 1000
s est très proche de 3 (3,72). Le problème est de
parvenir à déterminer ![]() correctement : nous classons les échantillons en ordre croissant
et nous calculons
correctement : nous classons les échantillons en ordre croissant
et nous calculons ![]() avec les n % plus petits (la méthode est relativement robuste
à n : nous prenons n=90).
avec les n % plus petits (la méthode est relativement robuste
à n : nous prenons n=90).
Supposons que nous ayons n fonctions de décision (c'est-à-dire n capteurs).
Supposons que la probabilité de bonne détection pour chaque fonction de décision soit pbd = 0,8. Plusieurs cas sont considérés :
Après la fusion, la probabilité de bonne détection est :
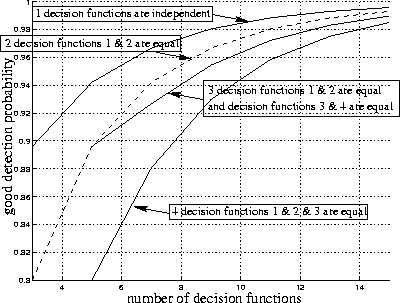
Deux fonctions de décision sont égales quand les fonctions d'observation correspondantes sont très corrélées. Ainsi nous pouvons voir qu'il est très important d'utiliser des fonctions d'observation très décorrelées.
La hauteur de chaque marque correpond à la confiance que nous lui accordons.

Pour trouver la note jouée sur chaque segment, ces trois mesures sont utilisées :