Segmentation et étiquetage
- Stéphane Rossignol -
La procédure de segmentation est hiérarchique.
Trois niveaux de segmentation sont définis. Les informations obtenues
à un certain niveau sont propagées vers les niveaux inférieurs
pour améliorer leurs performances. Les segments trouvés sont
de plus en plus petits et précisément étiquetés.
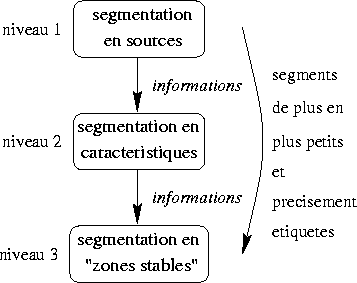
Segmentation en sources
Le but du premier niveau de segmentation est de classifier
le son suivant sa nature. Les deux classes considérées sont
la parole et la musique. Les sons utilisés sont par
exemple des bandes son de film ou des enregistrements radiophoniques.
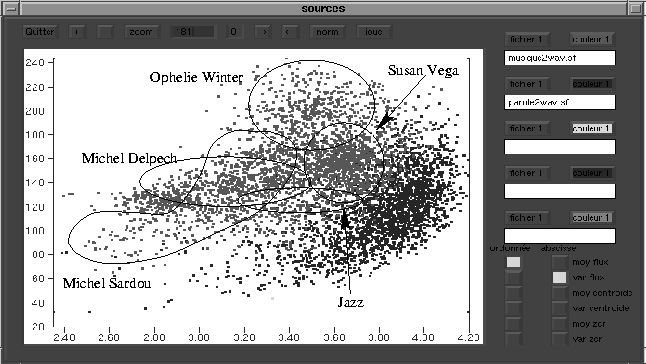
Exemple
Points clairs : musique
Points foncés : parole
Première fonction d'observation : moyenne du flux
spectral (ordonnée)
Seconde fonction d'observation : variance du flux spectral
(abscisse)
Segmentation en caractéristiques
Lors du niveau de segmentation en caractéristiques,
étiquetage des segments avec des caractéristiques du type
: silence/son, voisé/non voisé, harmonique/inharmonique,
présence
de vibrato/absence de vibrato...
Segmentation en zones stables
Il s'agit ici de poser des marques de segmentation sur un
son, dans le but d'obtenir des segments de son étiquetés
qui soient manipulables (recherche dans des bases de données), transformables...
Première étape : Extraction de fonctions d'observation
Deuxième étape : Prise de décision (seuillage)
Troisième étape : Prise de décision
finale (fusion de données)
Interface graphique: Visualisation de la décision
finale, la hauteur de chaque marque correpond à la confiance qui
lui est accordée
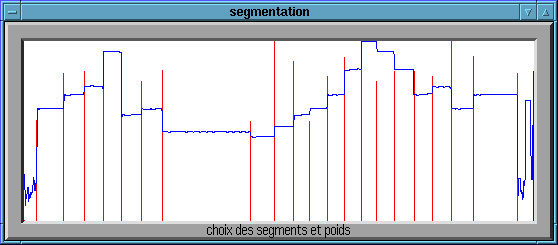
Quatrième étape : transcription automatique
Pour l'extrait de flûte :
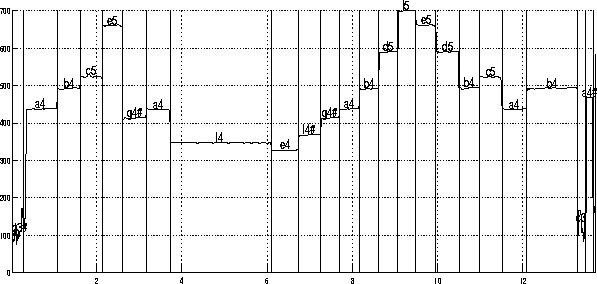
Présentation détaillée
->