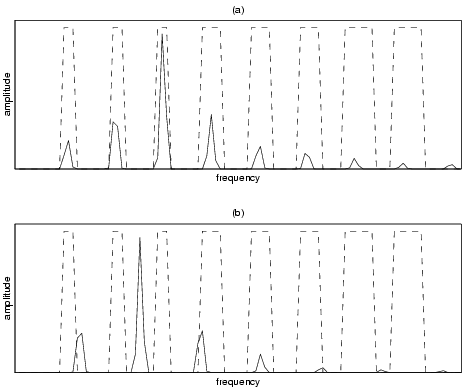
Figure 1: The generated spectral bands with a good (a), and a bad (b) matching performance spectrum.
Normalization of the results of || S · P2 || is necessary to prevent a loud, noisy frame from matching all generated bands. To this aim, its value is divided by the signal energy in the frequency range that contains all the rectangular spectral bands.
Figure 1: The generated spectral bands with a good (a), and a bad (b) matching performance spectrum.
| DPSD(m, n) = |
|
(2) |
| sPSD(m, n) = |
|
(3) |
| p(m, n) = min | { | 3 p(m-1, n-1) + 2 d(m, n) p(m-1, n)+d(m, n) p(m, n-1)+d(m, n) | } | (4) |
| d(m, n) = |
|
(5) |
Regarding the comparatively high offsets for legato articulation, listening to the found segments revealed that the algorithm chose to place the note onset where the overlapping partials of the previous note had sufficiently died down, which is actually better suitable for the application of building unit databases.
mono low mid high avg l 44 33 26 34 d 20 16 8 15 p 35 11 8 18 s 37 10 9 19 avg 34 18 13 23
poly low mid high avg l 58 36 35 43 d 26 18 15 20 p 33 13 7 18 s 35 10 9 18 avg 38 19 16 26
Table 1: Average offset in ms depending on articulation and octave, for monophonic and polyphonic scores.
This document was translated from LATEX by HEVEA.