Home page and Keele Workshop page.
1) Does target harmonicity play a role in scene analysis?
A proposition of Auditory Scene Analysis is that common harmonicity allows partials of a sound to form a figure that stands out from a background (either inharmonic, or of a different harmonicity from the target), and thus allows it to resist fusion or masking (Bregman, 1990). The fact that partials of a target share a common fundamental labels them as belonging together, and distinguishes them from components of interfering sounds. In the time domain, the target waveform is correlated with itself at a delay of a period or multiple, whereas the interference is uncorrelated.
This idea is exploited in models of Computational Auditory Scene Analysis (CASA) that group together spectrotemporal regions that are modulated by the same period (Weintraub, 1985; Cooke, 1991; Brown, 1992; Berthommier and Meyer, 1995; Meyer and Berthommier, 1996). Berthommier (1996) proposed to add the signal to itself at delays equal to the target period, to reinforce it relatively to the uncorrelated background. A similar scheme had been described by Frazier (1976).
Note that harmonicity can be exploited in a different way: the harmonic structure of interfering sounds can be used to eliminate them. In fact one would expect both strategies to be useful, and used whenever possible by the auditory system.
There are several questions one may ask:
a) Is target harmonicity useful?
One can show that the enhancement ratio of a scheme such as that of Frazier (1976) or Berthommier (1996) is at most equal to the duration in periods of the impulse response of the filter that implements it (de Cheveigné 1993a, Appendix A). That is, the gain is small unless the impulse response is long. If the target is speech, a long impulse response is unlikely to be effective because speech is not stationary over long periods. Adaptive (Frazier 1976) or time-warping (Graf and Hubing, 1993) filters address the problem of varying F0, but not other sources of non-stationarity.
Steady-state voiced portions of speech may be enhanced to a degree, but transitions or unvoiced portions won't benefit from harmonic enhancement. Enhancement requires that the fundamental frequency (F0) of the target be estimated, which is relatively easy if the target is strong, but difficult if the target is weak (when segregation is most necessary). Note that the opposite is true for the alternative strategy of harmonic interference cancellation: it is easy when the interference is strong.
Zissmann and Weinstein (1989) simulated an ideal cochannel speech interference suppressor. The "jammer" voice could be removed, leaving the target alone, either when the jammer was voiced (ideal cancellation), or when the target was voiced (ideal enhancement). The former gave better intelligibility scores. The explanation they gave was that voiced portions of the jammer contained most of the energy, so that removing them improved the SNR more than removing portions corresponding to the voiced state of the target.
Erell and Weintraub (1991) attempted to use pitch information for noise-robust speech recognition. Mean-square error was reduced, but there was no improvement in recognition, a fact that they explained by noting that spectral distortion of the log spectrum was overwhelmingly dominated by the unvoiced frames of the target.
We implemented a harmonic target enhancement scheme as a front end to a simple DTW word recognizer, to reduce the effect of cochannel speech interference. The improvement was small in comparison with that obtained by harmonic cancellation of the interference (de Cheveigné 1993a, 1994).
In summary, whereas harmonic target enhancement is appealing in theory, in practice it is limited by a) the difficulty of F0 estimation of a weak target, b) the limited effectiveness of enhancement filters, c) the lack of benefit for transitions and unvoiced portions.
b) Does the auditory system use target harmonicity?
Several lines of evidence suggest that this is not the case, at least as far as the segregation of steady-state targets (such as double vowels) is concerned.
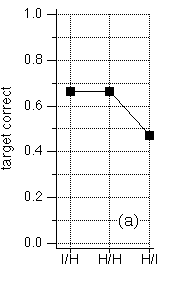
Lea (1992) presented subjects with mixtures of voiced and whispered vowels. Identification of a vowel was no better if that vowel was voiced than if it was whispered, but it was better when the interfering vowel was voiced. We came to the same conclusion with similar experiments (de Cheveigné et al. 1995, 1996b) (Fig. 1).
Fig. 1. Identification rate of a target vowel as a function of its harmonic state and that of the vowel that accompanies it (notation: target/ground). Targets were 15 dB weaker than accompanying vowels. Inharmonic vowels were obtained by random perturbation of the frequencies of a harmonic series.
In another experiment, we presented subjects with pairs of vowels that could differ in both F0 and level. Identification was measured separately for each vowel. The identification rate of the weaker vowel (-10 or -20 dB) was much higher when there was an F0 difference than at unison. This improvement is very unlikely to be the result of harmonic enhancement, as the auditory system would have had great difficulty in estimating the F0 of the weak target. Target F0 estimation might have been easier when the target was strong (+10, +20 dB), but effects were small in that case, possibly because of a ceiling effect (de Cheveigné et al. 1996a) (Fig. 2).
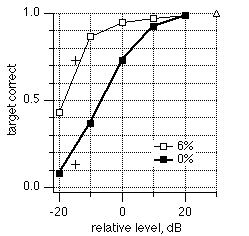
Fig. 2. Identification rate of a vowel as a function of its RMS level relative to the vowel that accompanies it, at unison (thick line) and at a deltaF0 of 6% (thin line). The triangle is for single vowels. The crosses are for a similar experiment with the same subjects, at -15 dB.
So far there is little evidence that the auditory system uses target harmonicity for simultaneous segregation. There is however evidence that stimulus harmonicity affects the number of sounds heard (de Cheveigné et al. 1996b). There is also evidence that the F0 track of a target voice must be continuous if the auditory system is to follow it (Bregman, 1990). Nevertheless, given the lack of support for grouping by target harmonicity in segregation of steady-state sounds, it is perhaps necessary to reexamine the role it is given in CASA models.
2) "Phonemic restoration": what is restored?
If a portion of speech is spliced out and replaced by a loud noise, listeners may be unaware that anything was missing (Warren, 1970, 1972). In that case they are also usually unable to say precisely when, within the word, the interruption occured. If the missing portion contains silence instead of noise, the disruption is clearly perceived, and can be easily located with respect to the intact speech events.
"Phonemic restoration" can be taken literally to mean that the auditory system has "filled in" missing evidence at several levels of representation in a top-down process involving schemas, or possibly a bottom-up process involving interpolation from neighboring spectro-temporal regions of intact information. The appeal of this interpretation is that it matches the subjective impression that the interrupted sound continues behind the noise. It is also parsimonious in the sense that, once they are restored, patterns are handled in much the same way as if they were intact in the first place.
This interpretation is implicit in several CASA models. Weintraub (1985) replaced missing partials by spectro-temporal interpolation. Cooke and Brown (1993) restored masked spectro-temporal patterns by interpolating harmonics before and after the masker. Ellis (1996) invokes a schema-driven top-down process that makes predictions that are "reconciled" with available evidence.
A different interpretation is that "phonemic restoration" is essentially a metaphor. The subject perceives the interrupted speech as continuous because it is the most likely interpretation given the evidence. The alternative interpetation, that the masked phoneme was absent, requires the unlikely assumption that the maskee was switched off precisely while the masker was switched on. If the masker is sufficiently strong to mask the presence (and therefore also the absence) of the maskee, and if a strong schema exists that is compatible with the intact evidence, then there is no reason for the subject to doubt that the maskee was present all along behind the noise. In coming to this conclusion the auditory system requires: a) the intact evidence, b) the schema, c) the noise. It does not require explicit reconstruction of intermediate representations. It could attempt such a reconstruction, but to what avail? Anhow, it is difficult to design an experiment (other than physiological) to prove or disprove this hypothesis (Repp, 1992).
Speech recognition provides an interesting viewpoint of this question. Cooke et al. (1996) compared several schemes to deal with missing spectro-temporal evidence (due for example to masking with helicopter noise) in a speech recognition sytem.
A first, crude scheme was to replace missing values by zero. Recognition rate was low, due to the fact that zero makes a poor match to reference patterns (HMM models). The analogue in the perceptual domain is fact that silence-interrupted speech has low intelligibility. Using a constant equal to the mean over the intact part of the spectrum, instead of zero, was little better.
A second scheme was to to estimate the missing part conditional on neighboring intact evidence. This is analogue to a bottom-up version of the first interpretation of "perceptual restoration", and to interpolation schemes such as that of Weintraub (1985). Missing evidence is restored before recognition is attempted. For random deletion of spectro-temporal patches, the recognition rate remained high even when up to 80% of the evidence had been removed. However with helicopter noise, during some time intervals, the entire spectrum was masked and the scheme could do no better than restore a mean spectrum. The average spectrum is also a poor match to reference patterns, so recognition rates were relatively poor.
A third scheme was to ignore missing values. Arguably this is better than try to make a guess, however educated. For example noise could have replaced a transitory feature such as a consonant, in which case interpolation between adjacent steady-state portions would produce strong evidence against the presence of the consonant, clearly the wrong thing to do. Missing values were ignored within the HMM framework by replacing full distributions by marginal distributions, calculated by integration over the missing dimensions. This third scheme ran into two practical difficulties. First, as the full spectrum was not reconstructed, it was not possible to calculate cepstral coefficients (that have the advantage of being orthogonal). As a result recognition rates were actually worse than with the conditional reconstruction scheme, for random spectro-temporal deletions. For helicopter noise however they were better. The second difficulty was that precise estimation of the marginal estimation required too many matrix inversions to be feasable without approximations[1].
In an experiment with a simple word recognition system (de Cheveigné 1993b, 1994), we implemented a stage of cochannel speech interference reduction based on harmonic cancellation. The cancellation filter removed all harmonics of the interfering voice fundamental, and thus improved recognition rates, especially at low signal-to-noise ratio. However it also distorted the spectrum of the target, reducing the quality of the match to unfiltered reference templates. The solution was to apply a similar distortion to the templates (Fig. 3). The identification rate was improved, particularly at high SNR.
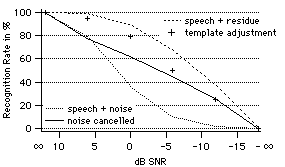
Fig. 3. Recognition rate as a function of signal-to-noise ratio for raw cochannel speech (lower dotted curve), harmonic cancellation (full line) and harmonic cancellation with template adjustment to compensate for the spectral distortion (crosses). The upper dotted curve is the ideal rate that would be obtained if there were no spectral distortion of the target (the target is added to the residual of cancellation of the interfering voice).
Applying the same spectral distortion to target and template has the effect of putting less weight on parts of the spectrum situated near harmonics of the interference. Energy at those frequencies cannot be assigned between the target or the interference, and thus it is of no use for recognition. Ignoring it in the recognition process is the best course.
In summary, if there is no empirical way of deciding whether perceptual phonetic restoration involves reconstruction of intermediate representations, and if speech recognition systems manage to proceed without it, it is worth questioning how litterally we should take the metaphor of phonemic restoration.
In the "third scheme" described above, spectro-temporal regions that were known to be masked were ignored. The masked regions were determined by comparing the SNR of the speech and masker before mixing: regions where the masker was stronger were flagged as masked. The Sheffield group (Green et al., 1995; Cooke, 1996) has also developped a scheme to deal with the "real" situation where the original speech and masker are unavailable, so masked regions must be guessed. In this scheme, target and template are matched by a loosened criterion that assigns no penalty to a spectro-temporal region where the target exceeds the template, as that might be the effect of masking. Wherever the target is weaker than the template, the difference is treated in the normal fashion (as "counter-evidence"). Green et al. (1995) also refer to this as "exploiting auditory induction".
This "counter-evidence" criterion is very loose, especially if there is uncertainty as to the overall level of the target, or if the masker is strong. It is appropriate if a masker can occur anytime, at any level, and in any frequency region. If the pattern of the noise is known or can be guessed, for example if it is localized in time (impulse noise) or in frequency (narrow-band or harmonic interference), or if its pattern in one region can be inferred from that in another (comodulated noise), then the "third" scheme described above is more appropriate.
"Bottom-up" CASA, in which segregated sounds are passed on to an unmodified recognition stage (or resynthesized), has been justly criticized (Cooke, 1996; Bregman 1996; Slaney, 1995; Ellis 1996). "Top-down" processes have been advocated instead. There is a third possibility: information flows bottom up, but in addition to the "segregated" sound, information about how the interference (or the segregation algorithm) might have damaged it is passed to the recognition stage. This might take the form of a spectro-temporal "confidence map". That is the idea behind the "third scheme" of Cooke et al. (1996) or our template adjustment scheme (de Cheveigné 1993b). It is not unreasonable to suggest that the auditory system proceeds in a similar fashion.
Intelligibility of severely filtered speech (Warren, 1996) might be interpreted in a similar fashion: the auditory system knows (how is a different question...) that certain frequency bands are missing, and replaces them by "wild-cards". It is interesting to note that, whereas phonemic restoration of a temporal gap requires the presence of noise, filtered speech is intelligible even if the stop bands are empty. However Warren (1996) notes that intelligibility of speech filtered in two narrow bands (1/20 octave, 370 Hz and 6000 Hz) improved when the gap was filled with noise.
Berthommier, F., and Meyer, G. (1995), "Source separation by a functional model of amplitude demodulation", Proc. Eurospeech, 135-138.
Berthommier, F. (1996), "Direct separation of sounds based on knowledge of F0 and ITD", this workshop.
Bregman, A. S. (1990), Auditory scene analysis, MIT Press: Cambridge, Mass.
Bregman, A. (1996). "Psychological data and computational ASA," in "Readings in Computational Auditory Scene Analysis," Edited by H. Okuno and D. F. Rosenthal, Laurence Erlbaum
Brown, G. J. (1992), "Computational auditory scene analysis: a representational approach.," Sheffield University unpublished doctoral dissertation.
Cooke, M. P. (1991), "Modelling auditory processing and organisation," Sheffield University unpublished doctoral dissertation.
Cooke, M. P. and G. J. Brown (1993), "Computational auditory scene analysis: exploiting principles of perceived continuity.", Speech Communication 13, 391-399.
Cooke, M. (1996), "Auditory organisation and speech perception: arguments for an integrated computational theory", this workshop.
Cooke, M., Morris, A., Green, P. (1996), "Recognising occluded speech", ths workshop.
de Cheveigné, A. (1993a), "Separation of concurrent harmonic sounds: Fundamental frequency estimation and a time-domain cancellation model of auditory processing.", JASA 93, 3271-3290.
de Cheveigné, A. (1993b), "Time-domain comb filtering for speech separation", ATR Human Information Processing Laboratories technical report TR-H-016.
de Cheveigne, A. (1994). "Strategies for voice separation based on harmonicity.", Proc. ICSLP, Yokohama, 1071-1074. [.pdf format]
de Cheveigne, A., H. Kawahara, K. Aikawa and A. Lea (1994). "Speech separation for speech recognition," Journal de Physique IV 4,C5-545-C5-548. [PS format]
de Cheveigné, A., Kawahara, H., Tsuzaki, M. and Aikawa, K. (1996a). "Concurrent vowel segregation I: effects of relative level and F0 difference," in preparation.
de Cheveigné, A., McAdams, S., Marin, M. (1996b). "Concurrent vowel segregation II: effects of phase, harmonicity and task," in preparation.
de Cheveigné, A., McAdams, S., Laroche, J. and Rosenberg, M. (1995). "Identification of concurrent harmonic and inharmonic vowels: A test of the theory of harmonic cancellation and enhancement," J. Acoust. Soc. Am., 97, 3736-3748.
A. de Cheveigné (1996). "A neural cancellation model of F0-guided sound separation.", this workshop. [PostScript (A4)]
Ellis, D.P. (1996), "Prediction-driven computational auditory scene analysis for dense sound mixtures", this workshop.
Erell, A., and Weintraub, M. (1991). "Pitch-aided spectral estimation for noise-robust speech recognition.", Proc. IEEE ICASSP, 909-912.
Frazier, R. H., Samsam, S., Braida, L. D., and Oppenheim, A. V. (1976). "Enhancement of speech by adaptive filtering.", Proc. IEEE ICASSP, 251-253.
Graph, J., Hubing N.(1993). "Dynamic time warped comb filter for the enhancement of speech degraded by white gaussian noise,". Proc. IEEE-ICASSP, 339-342.
Green, P.D., Cooke, M.P., and Crawford, M.D. (1995). "Auditory scene analysis and hidden markov model recognition of speech in noise," Proc. IEEE-ICASSP, 401-404.
Lea, A. (1992), "Auditory models of vowel perception", Doctoral dissertation, University of Nottingham.
Meyer, G.F., and Berthommier, F. (1996), "Vowel segregation with amplitude modulation maps: a re-evaluation of place and place-time models", this workshop.
Repp, B. (1992). "Perceptual restoration of a "missing" speech sound: Auditory induction or illusion?," Perception and Psychophysics 5,14-32.
Slaney, M. (1995). "A critique of pure audition.", Proc. Computational auditory scene analysis workshop, IJCAI, Montreal.
Summerfield, Q. and Culling, J.F. (1992 ). "Periodicity of maskers not targets determines ease of perceptual segregation using differences in fundamental frequency",124th meeting of the ASA [J. Acoust. Soc. Am. 92, 2317 (A)].
Weintraub, M. (1985), "A theory and computational model of auditory monaural sound separation", Doctoral dissertation, Stanford University.
Warren, R. M. (1970). "Perceptual restoration of missing speech sounds," Science 167,392-393.
Warren, R. M., Obusek, C. J., and Ackroff, J. M. (1972). "Auditory induction: perceptual synthesis of absent sounds," Science 176,1149-1151.
Zissmann, M.A. and Weinstein C.J.(1989). "Speech-state-adaptive simulation of co-channel talker interference suppression.", Proc. IEEE-ICASSP, 361-364.