Some Similarities and Differences
Richard M. Warren
email: rmwarren@csd.uwm.edu
Department of Psychology, University of Wisconsin-Milwaukee
P.O. Box 413
Milwaukee, WI 53201
USA
ABSTRACT
Understanding of speech perception can be enhanced by understanding how we recognize other sequences of brief sounds. In addition, studies of speech perception can lead to a deeper understanding of the general rules of auditory pattern perception. This reciprocity will be illustrated with examples drawn chiefly from three topics we have studied in our laboratory. The first topic concerns a sophisticated mechanism used to restore portions of verbal and nonverbal signals masked by extraneous sounds. The second topic concerns the organization of sequences of brief sounds, whether phones or nonspeech, into "temporal compounds" that are recognized without resolution into component elements. The temporal compounds heard with sequences consisting of brief steady-state vowels are English syllables and English words. Surprisingly, vowel sequences split into two simultaneous voices corresponding to separate spectral ranges, and this observation has led to the third topic dealing with spectral redundancy and spectral restoration.
1. PHONEMIC RESTORATION AND
AUDITORY INDUCTION
In 1970, I reported that when a speech sound or an entire syllable in a sentence was deleted and replaced by a louder noise such as a cough, the sentence seemed intact, and even when listeners were informed that a portion of the sentence was deleted and replaced by a cough, they could not identify the missing speech sounds nor could they locate the extraneous sound's position in the sentence (Warren, 1970; see also Warren & Obusek, 1971). A short time later, I reported that this "phonemic restoration effect" was a special linguistic application of a general ability to restore interrupted signals that I called "auditory induction" (Warren et al., 1972). The induction of continuity of sinusoidal tones was examined in some detail by alternating a tone with bandpass and band-reject noises having various spectral compositions as well as with sinusoidal tones with other frequencies. These experiments demonstrated that the interrupting sound needed to be a potential masker for the tone to be heard as continuous. These and other observations led to the following hypothesis that was crafted to include both verbal and nonverbal sounds: "If there is contextual evidence that a sound may be present at a given time, and if the peripheral units stimulated by a louder sound include those which would be stimulated by the anticipated fainter sound, then the fainter sound may be heard as present." To test the validity of this rule for speech, James Bashford and I carried out a series of experiments confirming the prediction that bandpass speech interrupted periodically with bandpass noise would seem to be continuous only if the interrupting noise was capable of masking the speech (Bashford & Warren, 1979, 1987).
It was noted by Warren (1982) that when 80-dB and 82-dB broadband noises were alternated, a "homophonic continuity" occurred, and the 80-dB level appeared to be continuous. Interestingly, the higher amplitude 82-dB noise, which was heard as a pulsed intermittent sound, appeared to be distinctly fainter than the continuous 80-dB level. Since a physical subtraction of 80 dB from 82 dB leaves a residue less than 80 dB, it was suggested (Warren, 1982) that auditory induction is a subtractive process, with a portion of the auditory representation of the higher amplitude inducer being reallocated for the perceptual synthesis of the absent segment of the lower amplitude inducee. It was reasoned that, since phonemic restoration appears to be a form of auditory induction (Warren, 1972, 1984), it should also involve reallocation of a portion of the auditory input provided by the inducer. However, while Bregman (1990) accepted the reallocation principle for the restoration of tones and noises (which he called the "old-plus-new heuristic"), he considered that phonemic restoration was different, and corresponded to a special "schema-driven" stream segregation, in which a Gestalt-type closure was accomplished without the reallocation of auditory input from noise to speech. Since previous experimental studies of phonemic restoration
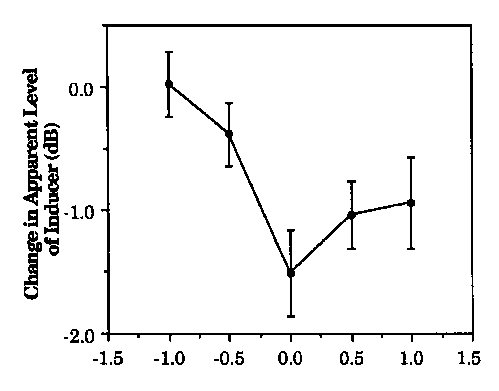
Figure 1. Auditory induction of speech (phonemic restorations): Means and standard errors for changes in the apparent level (loudness) of various noise-band inducers when interrupting an inducee consisting of a bandpass-filtered sentence. The 1/3-octave speech band had a fixed center frequency (CF) of 1500 Hz and a peak level of 70 dB. The 1/3-octave noise bands had levels of 70 dB and CFs that differed from that of the speech in 0.5 octave steps. The asymmetrical function represents a greater reduction in the apparent level of the noise when the speech had a higher CF.
were concerned with changes occurring in the speech and not the extraneous noise, Repp (1992) undertook a study designed to test the reallocation model by determining whether or not perceptual changes occurred in the quality of a noise when a phoneme was restored. He replaced the speech sound /s/ in a word with a noise having a different spectral profile than the /s/, and used rating scales to determine whether or not the listeners perceived a change in the timbre or brightness (not the loudness) of the interpolated noise when the speech sound was restored. It was reported that only two of his experiments demonstrated changes in noise timbre consistent with a reallocation of a portion of the auditory representation of the noise and three did not. Warren et al. (1994) designed a more critical test of the reallocation model for phonemic restoration. A narrrowband noise interrupted the narrowband sentence "Where are you now?" (on/off times 125 ms for each). Listeners matched the apparent amplitude of the noise using an adjustable level comparison noise of the same spectral composition that alternated with silence rather than speech (for further description see the caption for Figure 1). As the figure shows, the largest loudness reduction occurred with matching frequencies of noise and speech. The asymmetry in the loudness function results from the greater masking potential of the noise when its frequency was lower than the speech's. A similar asymmetry in the reduction of the inducer's loudness occurred when both the inducer and inducee were nonverbal sounds (Warren et al., 1994).
2. TEMPORAL COMPOUNDS FORMED BY SPEECH AND OTHER SEQUENCES
OF BRIEF SOUNDS
The second topic linking the processing of speech and nonspeech sounds concerns the perception of acoustic sequences. Since speech consists of an ordered series of phonemes, with different orders signifying different words (e.g., "cats" versus "cast"), it seems reasonable to assume that the ability to identify temporal order of successive sounds is required for listeners to understand speech. Yet, when listeners attempted to identify the order of items in a repeated sequence consisting of four unrelated nonverbal sounds, the threshold for order identification was a few hundred ms/item (Warren, 1968; Warren, et al., 1969). Since speech comprehension is possible when the average duration of phonemes is well below 100 ms (see Warren, 1982, pp. 119-120), it might be considered that the special nature of speech permits the temporal resolution of phonemes at very brief item durations. However, when repeated sequences of steady-state vowels were substituted for nonverbal sounds, the threshold for identification of order was about 100-125 ms/item (Thomas et al., 1970; Cole & Scott, 1973; Cullinan et al., 1977), a duration still greater than that of the average phoneme in speech. None of these studies with vowel sequences examined the perceptual consequences of reducing the durations below the threshold for order identification. Had they done so, some interesting phenomena would have been observed.
A series of studies with sequences of nonverbal sounds in our lab revealed that identification of order was not required to recognize and discriminate between permuted arrangements of brief items other than speech sounds. When the duration of these items was well below the threshold for order identification (down to 10 ms or less per item) listeners could still recognize different arrangements, and do so with ease (Warren, 1974a, 1974b; Warren & Ackroff, 1976; Warren et al., 1991). In order to deal with the possibility that temporal resolution of items occurs at a deep level not accessible to conscious awareness, a two part experiment was designed to demonstrate that acoustic sequences are not necessarily processed as auditory sequences (Warren & Bashford, 1993). In the first part of this study, listeners heard repeated sequences of ten sinusoidal tones of different frequencies, each tone having a duration of 40 ms (a value well below the threshold for identification of tonal order). It was found that listeners could discriminate between sequences that were identical except for a reversal in the order of two adjacent tones. In the second part of the study, it was demonstrated that listeners can distinguish between and recognize permuted segments of auditory patterns even when these segments are not themselves discrete items. Each of the tones in the repeating sequence of ten sinusoids was replaced by a different 40-ms segment of stochastic noise. The repeated sequence of the ten "frozen noise" segments did not consist of a succession of discrete sounds -- indeed when joined together, there were no longer ten individual sounds, but rather a single repeating sound having a distinctive "whooshing" character that repeated every 400 ms. When the order of two of the 40-ms noise segments was reversed, listeners could distinguish between the two patterns as they did with the tonal sequences, although the discrimination took somewhat longer. Based on this study, together with other supporting evidence, Warren and Bashford concluded that:
"... sequences of brief items, whether speech sounds, tones, or stochastic waveforms derived from noise, can be processed globally as complex patterns or temporal compounds, and that resolution into discrete components is not required for discriminating between different arrangements of the acoustic components. We suggest that it is misleading to consider acoustic sequences of brief items (such as the phonemes in speech) as perceptual sequences, and that the models of speech perception involving analyses into component phonetic segments may be inappropriate."
This last sentence was directed at models such as that proposed by Morais and Kolinsky (1994) who argued that there are "unconscious representations" of phonemes that are employed in speech perception, and that alphabetic literacy raises this otherwise inaccessible level to conscious awareness.
The concept that sequences of phones in speech are organized into linguistic forms without an initial analysis into phonetic elements brings us to the question of what sort of linguistic forms (if any) would be heard if the duration of items in repeated sequences of steady-state vowels were below the threshold for order identification. In order to answer this question, Warren et al. (1990) employed isochronous sequences of from three to ten different vowels. When the vowels had durations between 30 and 100 ms, the stimulus vowels could no longer be identified, and the sequences were transformed into verbal temporal compounds. Different arrangements of the vowels were heard as different verbal forms.
There are two noteworthy characteristics of the verbal organizations that are heard with vowel sequences. (1) Listeners hear syllables and words consisting of illusory consonants along with vowels that are often not present in the stimulus -- these verbal forms not only follow the phonotactic rules of English, but almost invariably consist of syllables that occur in English words. (2) A rather remarkable characteristic of the verbal organizations of vowel sequences is that listeners usually hear two simultaneous voices with different timbres, each saying something different. Chalikia and Warren (1994) found that typically one voice consists of spectral components below and the other above the well-established "crossover frequency" of about 1500 Hz (the crossover frequency divides speech into two regions that contribute equally to the intelligibility of broadband speech).
These illusory organizations observed with vowel sequences can provide useful information concerning mechanisms used to process everyday speech. Helmholtz considered illusions to be valuable research tools, since they are based upon mechanisms that normally function to enhance accurate perception, but are used inappropriately under unusual conditions (see Warren & Warren, 1968, pp. 140). Thus, illusions can be used to reveal aspects of normal perceptual processes that are usually not observed, much as pathology in medicine has been used to reveal normal physiological processing. While Helmholtz was referring to visual illusions, this principle is at least equally valid for auditory illusions, and perhaps especially so for illusions involving speech. Let us deal first with the observation that when the forms heard are not themselves English words, they consist of syllables that occur in English, with phonotactically legal syllables not found in English almost never occurring for native English speakers. This indicates that listeners possess not only an English lexicon, but also an English syllabary. Perhaps when listening to everyday speech, the accessing of polysyllabic lexical items is preceded by organization of the stream of speech sounds into a series of English syllables. These syllables can then be linked, when appropriate, to identify a word of more than one syllable. Since the number of English syllables appears to be considerably less than the number of English words (Denes & Pinson, 1993), an initial syllabic organization may represent an efficient processing strategy. Of course, comprehension of speech does not involve a simple bottom-up chaining of syllables, but a top-down (and possibly sideways) interaction with processes involving syntactic and semantic factors. Vowel sequences eliminate processes based upon higher level linguistic information, allowing us to examine products of lower level processing that are not normally isolable.
Next, let us turn to the spectral splitting into two verbal forms occurring at the crossover frequency. This spontaneous fissioning into two concurrent voices is quite surprising, considering the multiplicity of cues indicating that the sequence of vowels was produced by a single source. All spectral components of the vowels were harmonics of a common fundamental, and the phase relations of these components across the spectrum corresponded to pulses originating at a common source. The simultaneous onset and offset of the individual vowels served as a further cue for a single voice. Nevertheless, it appears that the linguistic forces for spectral fission overcame the acoustic cues for fusion. The separate organization of these two spectral regions suggests that this process may be employed normally to enhance comprehension under difficult listening conditions. Speech is, of course, highly redundant, and normal clear speech is perfectly intelligible when either high-pass filtered or low-pass filtered at the crossover frequency of 1500 Hz. The ability to organize different spectral regions separately may aid comprehension when speech is unclear due to the nature of a speaker's production, or to interference by extraneous sounds. The information from separate spectral organizations could be mutually supplemental and, when in agreement, could provide confirmatory evidence of accuracy.
3. SPECTRAL REDUNDANCY AND
SPECTRAL RESTORATION
The independent verbal organization of the spectral components of vowel sequences above and below 1500 Hz suggests that listeners can (and do) achieve intelligibility of normal speech (i.e., discourse) when many of the frequencies and features characteristic of individual phonemes are missing. We decided that it would be of interest to determine just how little spectral information is needed to understand everyday speech. The Articulation Index [ANSI-3.5, 1969 (1986)] describes the relative importance of different frequency regions to the intelligibility of speech, and is widely used in evaluating communication systems and acoustic environments. However, the Articulation Index was not designed for, and cannot predict the intelligibility of stand-alone bands of speech. For example, Pavlovic (1994) summarized some of the recent work involving the frequency importance function of the Articulation Index with a variety of speech stimuli including sentences and short passages of discourse, and reported that individual 1/3-octave bands in the vicinity of the crossover frequency provided the highest contribution to the intelligibility of broadband speech, with each band corresponding to 9% to 11% of the total information content. Nevertheless, Bashford et al. (1992) reported that bandpass sentences that were limited to only 1/8-octave in the vicinity of the crossover frequency (i.e., 1500 Hz) had intelligibility scores for keywords of over 95%. This high intelligibility of a narrow band is not inconsistent with the band importance function of the Articulation Index, since the redundancy of speech permits high intelligibility to be achieved with only a small portion of the total information content.
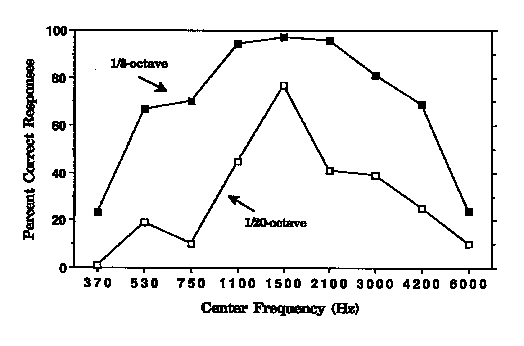
Since a search of the literature indicated that no systematic study of the intelligibility of stand-alone bandpass sentences had been reported, Warren et al. (1995) used CID "everyday speech" sentences (Silverman & Hirsh, 1955) and determined their intelligibility when heard through narrow spectral slits. Steep filter slopes were employed (about 100 dB/octave) with two bandwidths (1/3-octave and 1/20-octave). Separate groups of subjects (each presented with the same 100 CID sentences containing a total of 500 keywords) were used for the nine center frequencies employed with each bandwidth. The results are shown in Figure 2. It can be seen that very little spectral information is required to identify the keywords in the "everyday speech" sentences. Close to perfect intelligibility was obtained for 1/3-octave bands with center frequencies in the vicinity of 1500 Hz. Even with bands having a nominal bandwidth of 1/20-octave (produced by filter slopes of 115 dB/octave meeting at the center frequency), a score of better than 75% was achieved for a center frequency of 1500 Hz. This relatively high intelligibility would not be anticipated from an examination of the spectrograms of sentences limited to this extremely narrow band -- the spectrograms showed only a series of amplitude fluctuations occurring within a very limited frequency range.
As can be seen in Figure 2, the 1/20-octave bands centered at 370 Hz and 6000 Hz had very low intelligibilities. However, when Warren et al. presented both of these bands together, the intelligibility rose to more than double the sum of the intelligibility of each of
 Figure
2. Mean percentage of keywords reported correctly for CID "everyday speech"
sentences presented as 1/3-octave and 1/20-octave bands. Each data point
represents a different group of 20 subjects (total of 18 groups and 360
subjects).
Figure
2. Mean percentage of keywords reported correctly for CID "everyday speech"
sentences presented as 1/3-octave and 1/20-octave bands. Each data point
represents a different group of 20 subjects (total of 18 groups and 360
subjects).
the bands when presented alone, indicating that information in the two bands was being integrated synergistically despite the wide frequency separation. The combined intelligibility of these extremely narrow bands can be enhanced still further by the presence of noise. When these same two narrowbands were employed in a subsequent study by Warren et al. (in press), it was found that a "spectral restoration" took place that could increase the intelligibility of keywords in the CID sentences by more than 50% when stochastic noise was added to the gap separating the 370 Hz and 6000 Hz speech bands. As with phonemic restoration, the spectral restoration of intelligibility has a nonverbal analog. Houtgast (1976) reported that broadband noise presented at a level slightly below the masked threshold of a single sinusoid resulted in perception of the pitch of a missing fundamental that had previously been heard along with the sinusoid. In addition, Plomp and Larkin (cited in Plomp, 1981) reported that adjacent harmonics could be removed from a complex tone without influencing its timbre if listeners had been primed with the intact complex tone, and if the narrowband noise which replaced the missing region had a level sufficient to mask the harmonics had they been present in the signal. Thus, we see once again that general auditory mechanisms employed for nonverbal patterns are utilized to enhance the intelligibility of speech.
4. REFERENCES
ANSI-S3.5, 1969 (R1986). American national standard methods for the calculation of the articulation index.. New York: American National Standards Institute.
Bashford, J.A., Jr., Riener, K.R., & Warren, R.M. (1992). Increasing the intelligibility of speech through multiple phonemic restorations. Perception & Psychophysics, 51, 211-217.
Bashford, J.A., Jr., & Warren, R.M. (1979). Perceptual synthesis of deleted phonemes. In J.J. Wolf and D.H. Klatt (Eds.), Speech Communication Papers. New York: Acoustical Society of America, 423-426.
Bashford, J.A., Jr. , & Warren, R.M. (1987). Effects of spectral alternation on the intelligibility of words and sentences. Perception & Psychophysics, 42, 431-438.
Bregman, A.S. (1990). Auditory scene analysis: The perceptual organization of sound. Cambridge: The MIT Press.
Chalikia, M.H., & Warren, R.M. (1994). Spectral fissioning in phonemic transformations. Perception & Psychophysics, 55, 218-226.
Cole, R.A., & Scott, B. (1973). Perception of temporal order in speech: The role of vowel transitions. Canadian Journal of Psychology, 27, 441-449.
Cullinan, W.L., Erdos, E., Schaefer, R., & Tekieli, M. E. (1977). Perception of temporal order of vowels and consonant-vowel syllables. Journal of Speech and Hearing Research, 20, 742-751.
Denes, P.B., & Pinson, E.N. (1993). The speech chain: The physics and biology of spoken language (2nd Ed.). New York: Freeman.
Houtgast, T. (1976). Subharmonic pitches of a pure tone at low S/N ratio. Journal of the Acoustical Society of America, 60, 405-409.
Morais, J., & Kolinsky, R. (1994). Perception and awareness in phonological processing: The case of the phoneme. Cognition, 50, 287-297.
Pavlovic, C.V. (1994). Band importance functions for audiological applications. Ear & Hearing, 15, 100-104.
Plomp, R. (1981). Perception of sound signals at low signal-to-noise ratio. In D.J. Getty and J.H. Howard (Eds.), Auditory and visual pattern recognition. Hillsdale, NJ: Lawrence Erlbaum Associates, 27-35.
Repp, B.H. (1992). Perceptual restoration of a "missing" speech sound: Auditory induction or illusion? Perception & Psychophysics, 51, 14-32.
Silverman, S.R., & Hirsh, I.J. (1955). Problems related to the use of speech in clinical audiometry. Annals of Otology, Rhinology, and Laryngology, 64, 1234-1245.
Thomas, l.B., Hill, P.B., Carroll, F.S., & Garcia, B. (1970). Temporal order in the perception of vowels. Journal of the Acoustical Society of America, 48, 1010-1013.
Warren, R.M. (1968). Relation of verbal transformations to other perceptual phenomena. Conference Publication No. 42, Institution of Electrical Engineers (London), Supplement No. 1, 1-8.
Warren, R.M. (1970). Perceptual restoration of missing speech sounds. Science, 167, 392-393.
Warren, R.M. (1974). Auditory temporal discrimination by trained listeners. Cognitive Psychology, 6, 237-256. (a)
Warren, R.M. (1974). Auditory pattern discrimination by untrained listeners. Perception & Psychophysics, 15, 495-500. (b)
Warren, R.M. (1982). Auditory perception: A new synthesis. New York: Pergamon Press.
Warren, R.M. (1984). Perceptual restoration of obliterated sounds. Psychological Bulletin, 96, 371-383.
Warren, R.M., & Ackroff, J.M. (1976). Two types of auditory sequence perception. Perception & Psychophysics, 20, 387-394.
Warren, R.M., & Bashford, J.A., Jr. (1993). When acoustic sequences are not perceptual sequences: The global perception of auditory patterns. Perception & Psychophysics, 54, 121-126.
Warren, R.M., Bashford, J.A., Jr., & Gardner, D.A. (1990). Tweaking the lexicon: Organization of vowel sequences into words. Perception & Psychophysics, 47, 423-432.
Warren, R.M., Bashford, J.A., Jr., Healy, E.W., & Brubaker, B.S. (1994). Auditory induction: Reciprocal changes in alternating sounds. Perception & Psychophysics, 55, 313-322.
Warren, R.M., Gardner, D.A., Brubaker, B.S., & Bashford, J.A., Jr. (1991). Melodic and nonmelodic sequences of tone: Effects of duration on perception. Music Perception, 8, 277-289.
Warren, R.M., Hainsworth, K.R., Brubaker, B.S., Bashford, J.A., Jr., & Healy, E.W. Spectral restoration of speech: Intelligibility is increased by inserting noise in spectral gaps. Perception & Psychophysics (in press).
Warren, R.M., & Obusek, C.J. (1971). Speech perception and phonemic restorations. Perception & Psychophysics, 9, 358-362.
Warren, R.M., Obusek, C.J., & Ackroff, J.M. (1972). Auditory induction: Perceptual synthesis of absent sounds. Science, 176, 1149-1151.
Warren, R.M., Obusek, C.J., Farmer, R.M., & Warren, R.P. (1969). Auditory sequence: Confusion of patterns other than speech or music. Science, 164, 586-587.
Warren, R.M., Riener, K.R., Bashford, J.A., Jr., & Brubaker, B.S. (1995). Spectral redundancy: Intelligibility of sentences heard through narrow spectral slits. Perception & Psychophysics, 57, 175-182.
Warren, R.M., & Warren, R.P. (1968). Helmholtz on perception: Its physiology and development. New York: Wiley.