
ANNEXE : ARTICLE ICMC 1994
DEA D'INFORMATIQUE
UNIVERSITÉ PARIS XI
RAPPORT DE STAGE
présenté par
Augusto AGON
KANT : Une critique de la quantification pure.
IRCAM - Représentation Musicale
1 Place Igor-Stravinsky
75004 Paris.
PARIS, Septembre 1994.
"Nous ne pouvons comparer aucun processus au cours du temps - qui n'existe pas - mais seulement à un autre processus. C'est pourquoi la description du déroulement temporel n'est possible qu'en se fondant sur un autre processus"
Wittgenstein.
Je tiens à remercier tous ceux qui ont rendu possible ce projet, en particulier Gérard Assayag, Robert et Yvonne Oddos, Lionel Rokita et Athina Tsaparas.
Résumé
KANT est un nouveau modèle de quantification rythmique où une segmentation non périodique d'un flux de durées est effectuée sans connaissance a priori d'un tempo. La durée de la pulsation est calculée par un algorithme d'approximation équivalent à l'algorithme développé à l'Ircam pour l'extraction de la fondamentale virtuelle. Le résultat est une partition avec une structure métrique variable afin de grouper les structures musicales issues de la segmentation. Cette métrique est cohérente avec le résultat d'extraction du tempo. Ce modèle a été créé pour la quantification de structures temporelles complexes, lesquelles sont fréquentes dans la Musique Contemporaine.
Le projet de quantification rythmique KANT est développé depuis deux ans au sein du Département de Représentation Musicale de l'Ircam. Dès le début, on retrouve à la tête de ce projet, Gérard Assayag, Camilo Rueda et Joshua Fineberg. Véronique Vérière a réalisé des apports importants, lors de sa participation au projet en qualité de stagiaire.
KANT est donc le produit d'un travail collectif. Étant donnée l'excellente ambiance qui règne au sein du groupe, ainsi que les interactions entre ses différents membres, il paraît difficile d'attribuer à chacun les différentes réalisations ou mérites. Cependant, et en réponse à une question spécifique, j'exposerai les contributions apportées au projet pendant ma période de participation.
La premier pas fut l'élaboration d'un éditeur musical. Celui-ci a non seulement permis la combinaison de l'automatisme et de l'interactivité, mais de plus il a servi d'outil à la visualisation et au contrôle des différentes innovations apportées à notre modèle. Nous avons ajouté de nouveaux algorithmes de segmentation : notes répétées , silences longs, simultanéité verticale, segmentation à la main. Nous avons construit un moteur de segmentation qui s'appuie sur la reconnaissance d'information rythmique à l'intérieur de la séquence musicale, laissant ainsi les bases pour son extension aux espaces de hauteur et d'intensité. Cette méthode a débuté avec la recherche de motifs spécifiés par des expressions régulières ; elle a ensuite évolué vers la recherche de motifs maximaux, s'appuyant sur des critères de répétition de formes contiguës ou non contiguës. Grâce a ces ajouts notre modèle a trouvé une petite place dans le champ de l'analyse musicale. De même un protocole a été créé dans la segmentation, pour de nouveaux algorithmes définis par l'utilisateur.
Nous avons réalisé, en outre, des expériences afin de détecter la périodicité d'un événement ou d'un groupe d'événements dans la séquence et en déduire ainsi la pulsation; nous avons testé en particulier un modèle d'autocorrelation proposé par [Brown 93] . Cependant les résultats ont prouvé que ce type de méthode est spécifique au cas de la musique tonale, ce qui le situe en dehors de notre champ de prédilection.
Par ailleurs, l'usage de silences comme entrées possibles, ainsi que la visualisation et l'information polyphoniques ont commencé à avoir du poids à l'intérieur de notre modèle.
KANT a acquis au cours de cette étape une plus grande identité comme système de CAO[1], car outre sa grande interactivité nous avons constaté que - même en partant de durées générées aléatoirement -, le résultat final de la quantification obéit à une certaine logique, produit des différentes décisions à prendre lors du processus.
Nous sommes conscients que KANT en cet instant possède un statut de projet en cours, et assurément nous sommes loin de résoudre tout le problème de la quantification rythmique. Cependant notre modèle a été formalisé sur des bases solides, formalisation étendue aux différents points clés du problème. Cette représentation formelle d'un modèle de quantification rythmique est peut être l'apport le plus essentiel effectué au projet.
Les affirmations et prises de position dans le chapitre 1 ne reflètent pas la pensée de l'institution ni des autres participants du groupe de recherche.
Le problème, classique en recherche musicale, de la quantification rythmique peut se définir ainsi : conversion d'un flux de durées exprimées par des valeurs réelles en une structure rythmique, hiérarchique et discrète, qui puisse être exprimée de façon significative dans le système habituel de notation musicale. L'intérêt de la question provient du fait que beaucoup de compositeurs utilisent des formalismes numériques pour engendrer des configurations complexes de durées ; le problème se pose aussi de façon évidente dans le cas de la transcription automatique du jeu instrumental.
Divers modèles existent déjà, utilisant des techniques géométriques (distances euclidiennes) ou encore à base de réseaux d'automates. Cependant les solutions purement algorithmiques ne sont pas actuellement satisfaisantes dans le cas général, où l'on s'autorise des rythmes complexes, et où le contexte métrique n'est pas prédéfini - ce qui est le cas dans les quantificateurs du commerce. On constate alors souvent des solutions sémantiquement correctes, mais syntaxiquement aberrantes. Par ailleurs, une modification locale minime pourrait quelquefois optimiser le résultat, mais les systèmes existants sont en général incapables de détecter ce type de situations.
Pour mieux comprendre le problème de la quantification rythmique, prenons par exemple le flux de durées suivant, exprimé en secondes:
1.00 0.60 0.30 0.28 0.26 0.24 0.22 0.60 1.00
Une première solution à métrique et tempo données, 4/4 et 60 à la noire respectivement, peut être:

Cette solution, excellente au niveau de la précision, est presque impossible à interpréter. De plus, étant donné que le temps et la métrique ont été préétablis indépendamment de la pièce, la quantification ne reflète pas la structure de cette dernière. Une deuxième solution est proposée :

Nous observons clairement une structure de miroir ayant pour axe la seconde mesure. La notation de la seconde mesure reflète le léger accelerando qui s'effectue en elle, cependant la tendance actuelle est de proposer une notation plus simple et de déléguer à l'interprète l'exécution des petits phénomènes, tels que notre accelerando à l'intérieur de la seconde mesure. Ainsi nous proposons une nouvelle solution :

Ici, la seconde mesure a été notée comme un quintolet et ce sera à l'interprète d'exécuter l'accelerando, en fonction de la connaissance d'un style musical. Cependant la modification a été appliquée à toute la séquence, et non pas localement sur la seconde mesure. Nous avons perdu la symétrie entre la première et la troisième mesure, si bien que la première mesure présente une imprécision rythmique, étant donne que les valeurs 1.00 et 0.60 ont été égalisées. Nous présentons une dernière solution qui introduit des changements de tempo à l'intérieur de notre séquence :

Cette dernière solution, bien qu'elle réponde à nos attentes, peut aussi être critiquée. En effet, bien que le changement de tempo augmente le pouvoir expressif, il peut être aussi gênant dans l'exécution, surtout lorsque les intervalles de tempo sont petits.
En résumé, le problème de la quantification rythmique est un problème difficile, qui répond aux exigences individuelles. Au cours de ce mémoire nous nous attacherons aux points essentiels de ce problème, au fur et à mesure que nous exposerons les étapes différentes qui constituent notre modèle.
Le chapitre 1 donne une vision globale de la quantification rythmique. Nous adopterons des prises de position, concernant les principaux phénomènes qui interviennent dans la Musique, dans le but de soutenir nos idées fondamentales qui serviront de base à notre modèle de quantification. Le chapitre 2 s'attachera à la formalisation mathématique de notre modèle et à son exposition étape par étape. Le chapitre 3 exposera une méthode de segmentation appelée "par motifs", qui tente de tirer parti des différentes techniques de reconnaissance de motifs appliquées à d'autres domaines, afin de construire une technique particulière et extensible à d'autres champs musicaux au-delà du rythme. Nous présentons au chapitre 4 une implémentation de notre modèle dans l'environnement de programmation PatchWork. Nous donnons aussi un glossaire musical, ainsi que quelques conclusions et enfin l'ébauche de nos futurs travaux concernant ce projet.
En annexe, l'on trouvera un article qui résume notre modèle de quantification rythmique.
Affirmer que la musique est un art temporel implique plus que le simple besoin qu'elle a d'un temps physique pour s'exprimer dans un espace déterminé. Mais plus que cela il s'agit de déterminer les positions assumées à chacun des différents niveaux qui s'établissent à l'intérieur de ce cas particulier de communication. La plupart des auteurs se mettent d'accord pour différencier un temps physique et un temps musical. Ils associent au premier temps le réel et abandonnent au second le subjectif. Cependant si nous réfléchissons au concept de temps tout au long de l'histoire, nous arrivons à la conclusion d'une équivalence de certaines propriétés de ces deux temps. Quelle serait donc, la différence qui nous ferait penser à une telle division ?
Il n'est pas de notre ressort de donner des définitions du rythme ou du temps, encore moins d'en rechercher la genèse. Pourtant nous acceptons comme base l'inhérence du temps à la conscience sociale et individuelle. De plus nous nous aventurons à dire, qu'une fois cette prise de conscience effectuée, l'homme peut se servir de plusieurs sources d'information concernant le rythme, pour élaborer un concept du temps. Nous pouvons parler en particulier de rythme naturel : celui-ci impose les points d'articulation. Par ailleurs, le langage lui-même comporte implicitement un certain rythme : ce dernier après avoir été une des composantes créatrices du langage devient à son tour un élément de celui-ci. Lorsque nous parlons de langage, nous faisons référence non seulement au langage parlé, mais aussi à toute sorte de manifestations ou d'expressions, parmi lesquelles la Musique. Une autre métamorphose du rythme peut être trouvée dans les outils, générateurs de rythme, qui à son tour se transforme en outil. Le rythme s'impose par exemple dans l'agriculture avec des événements fortement marqués comme les périodes de semences et de récoltes. Mais c'est peut être dans le sacrifice et dans la vénération des dieux que le rythme trouve ses premières utilisations comme représentation symbolique. Nous ne pouvons pas affirmer qu'il y eut, à ces époques reculées, une différence entre le profane et le sacré ; les deux étaient intimement liés et la vie quotidienne et la vie religieuse ne faisaient qu'une. Les dieux étaient en relation profonde avec la nature et son usage, lequel, bien qu'il fut un acte quotidien, était soumis à des règles. La base des premières sociétés était donc de se servir de la nature. Nous pouvons dire que l'artisan était à la base de la civilisation ; ainsi les premiers musiciens étaient considérés avec le statut d'artisans, qui à leur tour étaient les truchements des dieux.
Suite à ces réflexions il convient de remarquer le phénomène suivant : il s'agit de l'élimination du temps qui s'appuie sur l'imitation d'archétypes. La cause se trouve peut être dans le besoin qu'a l'homme de régénérer son temps et d'échapper de la sorte au poids de l'histoire. Ainsi, et c'est la grande nouveauté, l'homme commence à imposer ses propres points d'articulations. Par exemple, une nouvelle année, une nouvelle décennie, les minutes, marquent le début d'une période que nous espérons recommencer, pour laquelle nous nous fixons des buts, enfin où nous répétons, peut être parce que, comme disait à peu près Heidegger, la répétition est l'épouse bien-aimée que nous ne pouvons abandonner, et c'est uniquement dans la répétition que l'homme peut être heureux.
Comme base de notre projet nous parlons d'un temps physique comme mesure d'un mouvement utilisant des points de repères donnés a priori, produit du phénomène cité auparavant, alors que nous parlons d'un temps musical comme de la position assumée devant un nouveau monde à découvrir et dont nous devons chercher le jour et la nuit afin de pouvoir vivre dans la Musique. C'est peut être lorsque nous commençons à conceptualiser un style musical que nous pouvons nous enhardir à proposer nos points d'articulation. Par exemple, nous parlons de l'exposition d'un sujet, d'un contre-sujet, du retour à la dominante, ou même nous pouvons suggérer un tempo qui prenne appui sur l'expérience stylistique.
Bref, nous associons au temps physique l'idée kantienne du temps vu comme une forme pure a priori de la perception. Alors que pour le temps musical, plus que faire participer le sujet et le son dans la temporalité de la musique, nous nous situons du côté d'une fragmentation du temps entre l'expérience vécue et les processus de production. C'est pourquoi la tentation d'une automatisation totale de la perception, comparable au concept de la théorie de l'invariance chez Adorno[1] , se trouve loin de notre propos. Adorno explique que l'élaboration d'une telle théorie devient impossible, vu que la conscience du temps musical varie d'une écoute à l'autre et c'est cette lutte intérieure pour nier le temps et l'espace empirique, qui rend la Musique charmante.
Mais alors qu'est-ce-que la quantification rythmique? Pour exprimer notre point de vue, nous distinguons trois niveaux dans le langage musical[2] : réel, imaginaire, symbolique. A la notion de réel nous associons la musique comme objet physique qui se déplace dans un certain milieu et qui parvient jusqu'à notre perception. L'imaginaire est associé à la conception que l'on se fait d'une pièce au niveau de la composition . Au niveau du symbolique nous situons la partition.
Ainsi nous définissons d'une façon assez globale la quantification comme la représentation symbolique d' un imaginaire en prenant comme référence un réel.
Sous l'éclairage précédent, une représentation rythmique en secondes des durées d'une pièce musicale est déjà une quantification et son interprétation produit un objet très proche de celui qui nous a servi de référence pour sa construction. De plus la-dite représentation numérique est accessible aux connaissances de tout le monde. Alors quel est le problème posé par une si bonne quantification? Principalement le problème est qu'elle exprime une idée en référence à un univers extérieur et non en rapport avec la Musique elle-même. C'est là notre plus grande critique quant à la quantification traditionnelle, qui part de la connaissance a priori d'un temps ou d'une métrique donnée, ce qui équivaut simplement à un changement de secondes en pulsations dans la représentation en temps physique. Ces représentations ayant comme défaut que nulle ne tire parti de l'information structurelle propre à la pièce.
Si nous prenons en compte pourtant la vérité consensuelle que possède une représentation en temps physique, nous redéfinissons le problème de la quantification rythmique d'une façon plus simple : la transcription "optimale" d'un flux de durées, dans le cadre de la notation symbolique de la musique. Affirmer qu'une quantification est "optimale" ou non dépend de divers facteurs individuels, car en tant que représentation symbolique d'une entité pensée, nous ne prétendons pas que la partition nous décrive l'entité comme telle, mais nous la voyons plutôt comme un usage [3] .
En [DH 92] on parle d'une division du temps musical en deux échelles temporelles : un temps discret, qui correspond aux intervalles d'une structure métrique et un temps continu, qui représente des phénomènes tels que accelerandos, rallentendos, etc... A ce stade nous émettons une objection à la confusion entre le temps musical et la représentation proprement dite de ce temps. On accepte une telle affirmation pour la représentation même si elle est aussi discutable. Pour nous le temps musical peut être vécu de la même façon que le temps physique, même s'il y a des différences remarquables entre les deux ; par exemple, le premier possède un début et une fin, ce qui en pratique modifie l'intention de l'auditeur.
Ainsi, pour nous, la quantification se réduit à deux grandes étapes :
- D'abord il s'agit de trouver une relation qui nous permette de passer de la représentation en temps physique à une représentation en temps musical. Cette relation, plutôt que de s'inscrire dans la représentation en temps physique, devrait être construite en accord avec des critères personnels. Ceux-ci pourraient être associés à nos connaissances et surtout à nos propres expériences même extra musicales, bref, à ce qu'il convient d' appeler notre style.
- La deuxième étape, non moins importante, est celle de la représentation symbolique de la perception musicale de l'oeuvre ; on peut émettre plusieurs critiques quant au système de notation musicale traditionnelle, entre autres le manque d'information sémiotique, le manque de précision de la notation, -spécialement en ce qui concerne les phénomènes de changement de tempo -, l'ambiguïté que représentent les différentes représentations d'un même objet, l'impuissance à exprimer exactement une valeur désirée, etc... Malgré les problèmes que cela soulève, nous avons choisi pour notre représentation le système de notation musicale traditionnel. En effet il s'agit là de la façon la plus universelle d'écrire la Musique. De plus, la création d'un nouveau système de représentation, ou la modification du système traditionnel est une tâche qui n'est pas dans l'intention de notre projet.
Concernant les critères pertinents d'une bonne quantification, nous dégagerons trois facteurs fondamentaux :
- Tout d'abord nous voulons que l'usage de notre représentation symbolique nous mène à un réel qui coïncide avec l'imaginaire placé dans l'acte de la création. On appelle ce critère la précision rythmique.
- Le deuxième critère est ce que l'on appelle simplicité de la notation. Il est tributaire des déformations possibles de notre entrée ou de la méconnaissance des intentions symboliques.
- Le dernier critère est l'apport d'information ; nous espérons que la partition nous apporte de l'information concernant les différentes sous-structures musicales et les connexions établies entre elles.
Par la suite nous allons effectuer une révision des différents problèmes posés par les quantificateurs industriels, afin d'y reconnaître les différentes motivations de notre modèle :
- Une métrique régulière et un tempo propres à toute la pièce doivent être donnés avant le processus de quantification. En musique tonale le temps est soumis à des règles formelles qui servent à une certaine logique de la composition. Cependant dans les nouvelles tendances contemporaines le temps se réduit à un ensemble d'instants organisés rationnellement. Ceci implique qu'un essai de quantification d'une pièce contemporaine par un quantificateur traditionnel n'exprime absolument pas la structure rythmique d'une telle pièce. En musique contemporaine, des modifications de métrique et de tempo enrichissent le pouvoir d'expression du langage. Notre but est de considérer un modèle de quantification qui prenne la musique tonale comme un cas particulier de l'organisation des idées dans le temps.
- Le contrôle des différents paramètres s'effectue au niveau global, dans la mesure où il n'existe pas de hiérarchie permettant l'application d'opérateurs à plusieurs niveaux.
- Les quantificateurs sont monodiques. Nous traiterons les séquences polyphoniques dans l'intention de renforcer la consistance verticale et d'obtenir par la suite l'information contenue dans la structure polyphonique.
- Le principal problème posé par ces quantificateurs est peut-être leur manque d'efficacité pour identifier et traiter les différentes modifications introduites dans l'interprétation, la plupart du temps, par la connaissance d'un certain style musical. Généralement, de nos jours la notation tend vers une certaine simplification ; les intentions du compositeur sont directement transmises par lui-même à l'interprète. Le processus de quantification doit être capable de trouver un équilibre entre simplicité et précision, en tenant compte des intentions de l'utilisateur.
En accord avec ce que nous avons exposé précédemment, nous avons développé un modèle de quantification rythmique dans le cadre de la C.A.O, c'est à dire, dans une perspective qui serait plus créative et productive que simplement de reconnaissance.
Nous partons d'un matériau engendré, que le compositeur espère en général porteur de forme. C'est donc au sein de ce matériau même qu'il faut chercher les informations de structures telles que la métrique et le tempo. Une quantification à métrique donnée dans un contexte de C.A.O. est une absurdité en soi. Comme toute composante d'un système de C.A.O, celle-ci est hautement interactive. Le compositeur peut indiquer au programme des traits de structure saillants que ce dernier ne pourrait deviner, d'autant plus que ces traits peuvent être liés à des paramètres musicaux externes aux strictes durées. Notre modèle dispose de bases de règles personnalisables. Par exemple la préférence peut être donnée localement à la simplification visuelle, (économie de signes) ou bien à la précision rythmique (augmentation du nombre de symboles rythmiques et de liaisons de durées pour matérialiser les divisions pertinentes du tempo).
La représentation formelle de quelques phénomènes musicaux est d'abord donnée. Elle nous sert de base pour la présentation de notre modèle de quantification.
Les lettres minuscules indiquent que les unités mesurant le phénomène en question sont exprimées dans e, les majuscules pour leur part indiquent qu'il s'agit des valeurs dans E.
La notation [[Pi]]i ( X) , représente la projection de X sur i.
Nous reformulons le problème de la quantification comme la transformation de e dans E suivi d'une description de E dans le système d'écriture musicale traditionnelle, c'est à dire une discrétisation de E .
Définition 2.1.
Un événement sonore est un point dans l'espace vectoriel es.
es = (d, o, v) ,
où d est l'axe des durées exprimé en centièmes de seconde (ces unités sont imposées par le matériel de mesure existant). o est l'axe des attaques , c'est à dire l'instant t par rapport à une valeur to où t est le début de l'événement sonore . L'axe v peut être vu comme l'information concernant le timbre de l'événement ; ainsi un numéro de voix est associé à chaque événement.
La définition équivalente à un événement sonore peut se faire sur l'espace vectoriel
ES = (D, O, V) v = V.
Graphiquement, nous représentons une événement sonore par :

Notons que la définition précédente ne fournit pas d'information sur la hauteur et l'intensité (une discussion à ce sujet est présentée dans le dernier chapitre).
Définition 2.2.
Une séquence monodique s est une suite d'événements sonores
n1,n2,...,nm tq.
i) pour tout i, j
[[Pi]]v (ni) = [[Pi]]v (nj) 1 <= i,j <= m
ii) pour tout i
[[Pi]]o (ni) + [[Pi]]d (ni) = [[Pi]]o (ni+1) 1 <= i,j < m
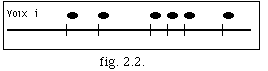
Définition 2.3.
Une séquence musicale sm, est un ensemble fini de séquences monodiques
{s1,s2,...,sn}, tq.
[[Pi]]o (first (si)) = [[Pi]]o (first (sj)) pour si , sj [[propersubset]] sm.
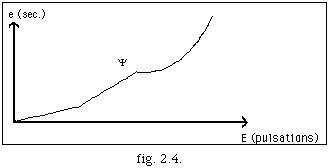
L'idée principale est de pouvoir rattacher e et E. Pour cela nous formulons l'axiome suivante:
Il existe une transformation [[Psi]]
[[Psi]] : E -> e
tq. e = [[Psi]](E) est une fonction continûment différentiable.
Un tempo rapide (cte), suivi d'un tempo lent (cte), suivi d'une décélération.
Définition 2.4.
La courbe de tempo associée à une transformation [[Psi]] est définie par :
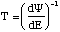 [pulsations / sec].
[pulsations / sec].
On a supposé que [[Psi]] est une courbe différentiable en tout point. Le cas de changements brusques de tempo, où la dérivé n'est pas définie, sera traité ultérieurement.
Ainsi, si on connaît un temps initial eo , la transformation [[Psi]] peut être exprimée par l'équation suivante:
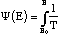 dT (eq.
2.1)
dT (eq.
2.1)
Définition 2.5.
Une archimesure A est définie comme un quadruplet :
A = (E[[omicron]], Ef , T, N)
avec
E[[omicron]] le temps initial .
Ef le temps final de l'archimesure, E[[omicron]] < Ef.
T une courbe de tempo dans l'intervalle [E[[omicron]] , Ef].
N une séquence musicale
tq.
i) Pour tout événement sonore n [[propersubset]] N, la projection de n sur O est dans l'intervalle [E[[omicron]] , Ef].
ii) Dans le cas polyphonique la projection du premier événement de chaque voix sur O doit être égal à E[[omicron]] et la projection du dernier événement sur O plus sa durée doit être égal à Ef.
Une archimesure peut aussi être représentée par un ensemble de mesures dont la définition est la suivante :
Définition 2.6.
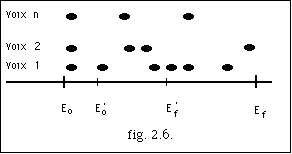
Soit A = (E[[omicron]] , Ef , T, N) une archimesure, on définit M une mesure de A comme un triplet
M = (Eo' , Ef' , T' )
où
E[[omicron]]' est le temps initial.
Ef' est le temps final, Eo <= Eo' < Ef' <= Ef.
T' la courbe de tempo dans l'intervalle [Eo', Ef'[.
Proposition 2.1.
Soit A = (Eo, Ef , T, N) une archimesure, on peut également exprimer A par
(N', M) avec M représentant un ensemble de mesures de A {M1,M2,...,Mn} et N' une séquence musicale, si les conditions suivantes sont respectées :
i)
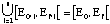
ii)
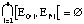
iii) N' = [[Gamma]][[Alpha]] ([[Nu]]).
Le fait qu'un événement ne doit appartenir qu'à une seule mesure n'est pas imposé. Le début et la fin d'un événement peuvent appartenir à des mesures différentes. Par contre il est clair que pour toute n [[propersubset]] N il existe Mi tel que la projection de n sur O est dans l'intervalle [Eo'i , Ef'i[.
Cette représentation des archimesures par un ensemble de mesures introduit une transformation [[Gamma]][[Alpha]] : séquence musicale -> séquence musicale.
A l'égal des archimesures on peut exprimer les mesures en fonction d'un ensemble d'éléments respectant certaines conditions. Ces éléments sont appelés pulsations[2].
Définition 2.7.
Soit A une archimesure et M = (Eo', Ef', T') une mesure de A, une pulsation B de M est un triplet
B = (D, k, T'' )
avec
D la durée de la pulsation.
k un entier appelé numéro de pulsation, 0 <= k .
T'' la courbe de tempo dans l'intervalle [Eo'' , Ef''[.
où
Eo'' =
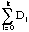 et Ef'' =
et Ef'' =
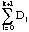
et Di la durée de la i-ième pulsation.
Cette définition nous permet d'avoir des changements de tempo à l'intérieur d'une mesure.
Proposition 2.2.
Soit A = (N,M) une archimesure et Mi [[propersubset]] M une mesure (Eo', Ef', T' ) de A, on peut représenter Mi par l'ensemble de pulsations B {B1,B2,...,Bm} si :
i)
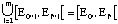
n
ii)
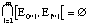
Les définitions que l' on vient de donner sont valables dans le temps E. Des définitions analogues à celles-là sont réalisables dans e .
Sur la base des définitions précédentes, on représente une pièce musicale par l'archimesure
a = (eo , ef , T , n)
où n est la séquence musicale correspondant aux entrées du système (chaque ni est exprimé dans e).
Le problème de la quantification se limite à trouver A = (Eo , Ef , T , N), suivi d'une représentation de A dans le système de notation musicale traditionnelle (i.e. q , e , h).
Étant donné que si l' on connaît T on peut trouver [[Psi]] (eq. 2.1 ) et qu'en connaissant e[[omicron]] ,
ef on trouve E[[omicron]] et Ef , car eo = [[Psi]] (E[[omicron]]) et ef = [[Psi]] (Ef) de même que pour n=[[Psi]](N),3 notre premier problème se limite à trouver T ; plutôt que de chercher la courbe T, nous allons la construire.
Après une étape de prétraitement, notre modèle, peut se diviser en quatre processus principaux, à savoir :
- segmentation en archimesures, segmentation en mesures, extraction du tempo, pour trouver A=(Eo,Ef,T,N) et
- quantification, pour la réécriture en notation musicale.
L'étape de prétraitement consiste à mettre la polyphonie à plat, c'est à dire que l' on projette les événements sonores de toutes les voix sur une seule voix virtuelle, en conservant cependant pour chaque événement sonore son numéro de voix. Donc, à la différence d'autres approches, la polyphonie est, pour nous, le cas général et la monodie est un cas particulier de polyphonie. Aussi nous obligeons toutes les voix à finir sur le même temps ; pour cela, on ajoute éventuellement des silences à la fin de certaines voix.
L'idée d'identifier des points d'articulation, qui puissent servir à la segmentation de notre séquence musicale, servira de base pour les deux premières étapes. Un point d'articulation est un trait de structure saillant dans le matériel musical. On associe ces points d'articulation à l'idée d'accent musical coïncidant avec le début d'une entité musicale. Ainsi tout attaque est déjà un point d'articulation qui indique le début d'un événement sonore. Plusieurs niveaux de hiérarchies peuvent se développer sur ce principe de points d'articulation. Pour être cohérents avec la propriété de minimalité de l' événement sonore, nous exigeons de notre modèle que tout point d'articulation coïncide avec l' attaque d'un événement sonore dans notre séquence musicale.
Plusieurs critères jouent un rôle important dans la détermination d'un point d'articulation. Bien que dans notre modèle chaque critère soit exposé d'une façon indépendante, nous rappelons le danger que représente le fait de traiter les différents facteurs rythmiques isolément. En outre on remarque que les accents ne sont pas des qualités absolues, car un événement est toujours accentué par rapport à un ou plusieurs autres événements.
Il n'existe pas une méthode de segmentation universelle. En général les résultats des diverses techniques sont meilleurs ou pires , selon un prédicat qui exprime l'intention de la segmentation. Avant d'entrer dans l'étude des différents niveaux et méthodes de segmentation utilisés dans notre modèle, nous présentons brièvement les différentes techniques de segmentation, afin de pouvoir mieux comprendre et d'y placer mieux nos propositions. Pour approfondir ce sujet voir [Fu 82] .
On peut diviser les techniques de segmentation en trois grandes classes :
i) Recherche de Seuil (thresholding).
Dans notre cas unidimensionnel, la recherche de seuil peut être décrite mathématiquement par :
S(x) = k si Tk -1 <= f(x) < Tk ,
où x identifie un élément dans notre séquence musicale. S(x) est la fonction qui associe à un événement une classe dans un ensemble de classes produit d'une partition de l'espace de caractéristiques (features) de nos événements. f(x) est la fonction de caractéristique, et To,..., Tm sont des niveaux de seuil, avec To le minimum et Tm le maximum. On remarque trois subdivisions dans cette technique: statistique, structurelle et de regroupement (clustering).
ii) Détection d'axes.
Cette technique est basée sur la détection de discontinuités i.e. l'endroit où il y a un changement abrupt d'intensité. Deux catégories peuvent se distinguer à l'intérieur de cette technique :
- Détection parallèle : pour décider quels sont les points de frontière, on applique un opérateur sur ces points et éventuellement sur quelques points voisins.
-Détection séquentielle : le résultat de l'application de l'opérateur à un point donné dépend des résultats des applications précédentes de cet opérateur.
iii) Extraction de régions.
Comme son nom l'indique, le principe de cette technique est de diviser la séquence à analyser en régions. Trois catégories peuvent être distinguées dans l'extraction de régions :
-Region Merging[4]
-Region Dividing[5]
-Region Dividing & Region Merging[6]
2.2.1 Segmentation en archimesures.
Pour traiter le problème des courbes de tempo non continûment différentiables, nous définissons une opération de concaténation CA.
CA : A x A -> A
Proposition 2.3.
Une archimesure A = (Eo, Ef , T, N) peut être vue comme la concaténation de plusieurs archimesures
A = (...(A1 CA A2) CA A3) ... ) CA An ,
si les conditions suivantes sont remplies :
i) dTi/dE = cte pour toute Ai.
ii) Eoi = projection (first Ni) sur O pour i= 1...n
Efi = projection (last Ni) sur O + projection (last Ni) sur D
iii)
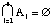 [7]
[7]
iv) Efi = Eoi+1 pour i = 1 ... n-1.
v) Pour toute i il existe j tq
Eoi = projection (j-ième événement de N) sur O.
La condition i) implique que la courbe de tempo doit être linéaire. Des combinaisons d'accelerandos, rallantendos et tempi constants ne peuvent pas se présenter à l'intérieur d'une archimesure.
La condition ii) nous dit que l'attaque du premier événement de chaque voix dans Ni doit coïncider avec Eoi pour i = 1...n , de même pour la terminaison dans chaque archimesure. Compte tenu de cette condition, une première transformation [[Gamma]]1 sera appliquée à notre séquence d'entrée. L'exemple suivant expose clairement cette situation :
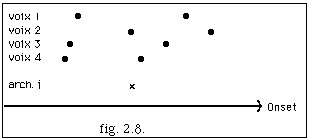
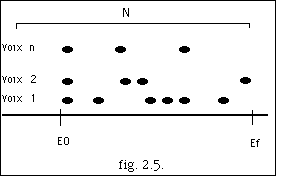
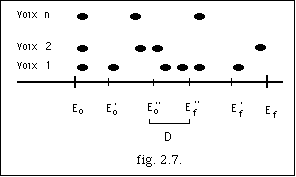
La figure 2.8. montre la projection d'une série d'événements sonores, appartenant à 4 voix différentes. Le symbole x représente la position Eoi, début de l'archimesure. La condition v) est satisfaite car x coïncide avec * pour la voix 2. Cependant pour les voix 1, 2 et 4 la condition ii) n'est pas satisfaite, ce pourquoi on modifie la suite d'événements en introduisant 3 nouveaux événements, ainsi :
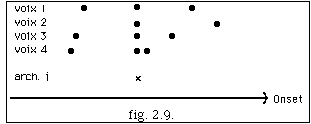
Des appoggiatures non désirées peuvent se créer à cause des nouveaux événements (voix 4 fig. 2.9).Pour résoudre ce problème, on trouve une valeur delta basée sur les entrées du système. Cette valeur nous sert comme critère pour décider de l'élimination ou non d'une note. Le résultat final, après la nouvelle archimesure i, est :
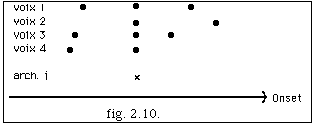
La transformation [[Gamma]]1 : sm -> sm sera l'identité dans le cas où il n'y a pas de segmentation ou si toutes les archimesures respectent la condition ii). [[Gamma]]1, de même que les autres transformations, se justifie par notre intention de modifier notre entrée pendant le processus, ce qui donne une perspective créative à notre modèle.
Dans cette première étape, on trouve donc les points de segmentation pour diviser notre séquence musicale en archimesures. Pour l'instant trois techniques différentes sont proposées pour la segmentation en archimesures :
2.2.1.1 Segmentation manuelle.
La segmentation manuelle peut être vue comme une entrée du système correspondant à une liste des attaques qui marquent le début et la fin d'une ensemble d'archimesures. On ne pense pas cette méthode comme une connaissance a priori, puisque différentes représentations de la séquence musicale, ainsi que le résultat des automatismes, servent d'aide pour prendre une décision sur les points d'articulation à ce niveau là.
2.2.1.2 Segmentation par densités.
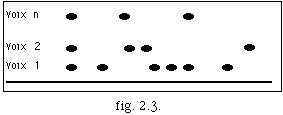
Cette technique peut être plus compréhensible si on représente la séquence musicale par un graphique où l'axe x représente un indice d'événement sonore dans la séquence musicale, et où l'axe y représente la durée de chaque événement (fig. 2.11).
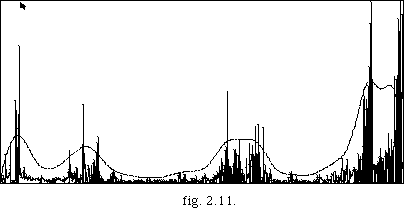
Par un simple lissage de la courbe on se fait une idée de la distribution de densité des événements dans le temps. A ce niveau de segmentation on s'intéresse aux régions centrées par rapport aux maxima et minima. L'explication de l'identification de ces régions, est en ce qu'elles déterminent des zones de tempo homogènes.
Différentes techniques de segmentation appliquées à d'autres domaines - parole, image, biologie, etc.- sont analysées afin d'évaluer leur utilisation possible.
2.2.1.3 Recherche d'accelerandos et rallentendos.
Cette méthode nous permet de traiter des séquences comportant des figures rythmiques simples mais continûment accélérées ou décélérées. Le fait de traiter ce type de séquences avec un tempo constant provoque une notation trop compliquée. Il est donc préférable de considérer un tempo qui varie de manière continue.
Afin de calculer ce tempo l'on suit le processus suivant :
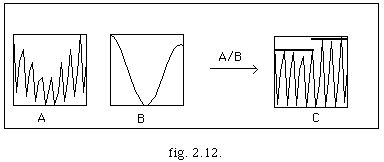
Nous représentons la séquence musicale en utilisant le système de coordonnes décrit au 2.2.1.2 (fig. 2.12 A). Par simple lissage de cette courbe nous obtenons une deuxième courbe (fig. 2.12 B). Nous effectuons tout de suite la division de la première courbe par la seconde : le résultat obtenu est une troisième courbe (fig. 2.12 C). Nous procédons à l'identification des zones de densité constante. Les paramètres de densité et de longueur significatifs de ces zones sont donnes comme entres au système. Cet ensemble de zones correspond à une segmentation en archimesures.
On a également défini des opérations logiques (Union, Intersection, Différence) pour les différentes techniques de segmentation en archimesures, de même que des modifications à l'intérieur d'une segmentation donnée, ceci pour donner la possibilité de construire une segmentation finale en prenant en compte plusieurs critères.
Après avoir déterminé une segmentation en archimesures, notre problème se limite à trouver les différents Ti pour chaque archimesure i. Cette recherche de Ti se fait indépendamment pour chaque archimesure.
2.2.2. Segmentation en mesures .
De la même façon que pour les archimesures, on définit une opération binaire CM entre une archimesure et une mesure :
CM : A x M -> A
Proposition 2.1
Soit A = (E[[omicron]], Ef, T, N) une archimesure, on peut exprimer A comme :
A = (...((nilA CM M1) CM M2) CM ... )CM Mn ,
où nilA est l'archimesure vide et M1,...,Mn est un ensemble de mesures satisfaisant :
i)
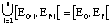
ii)
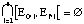
iii) Pour toute Mi il existe j tq.
Eo'i = projection (j-ème événement de N) sur O
Plusieurs méthodes de segmentation en mesures sont proposées :
2.2.2.1. Segmentation Manuelle.
Cette méthode correspond à la même idée que la méthode de segmentation manuelle en archimesures.
2.2.2.2. Notes Longues.
L'idée de cette méthode repose sur le principe musical d'accent agogique, qui peut se résumer ainsi :"sont accentuées des durées longues qui suivent des durées plus courtes."[8]
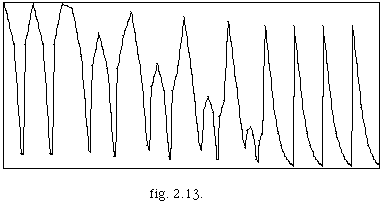
La représentation utilisée dans le paragraphe 2.2.1.2. nous donne une vision claire de cette méthode.
Dans la figure 2.13 le repère de notes longues peut être vu comme la recherche de pics maximaux. Une opération de lissage, invariante dans le temps, est utilisée afin de dégrader ou masquer certains pics secondaires.
2.2.2.3 Notes Courtes.
De même que pour les notes longues, les notes courtes sont accentuées, mais à la différence des notes longues elles localisent un certain groupe de durées courtes qui tend à être identifié comme un accent. Dans la fig. 2.13. les notes courtes correspondent aux pics minimaux de la courbe. Le segment est placé au début de l'intervalle défini par le groupe de durées courtes. Une opération de lissage est aussi proposée pour cette méthode.
2.2.2.4 Silences Longs.
Cette méthode a simplement pour tâche de repérer les silences, (indépendamment du contexte), dont les durées sont supérieures à une valeur donnée.
2.2.2.5 Accords.
Une méthode de segmentation sur le critère d'accords est proposée, en essayant de tirer parti de l'information polyphonique donnée.
On cherche dans la projection des événements sur l'axe des attaques, un ensemble d'intervalles I = {I1,...,In} tq, pour tout Ii appartenant à I,
i) Le nombre d'événements sonores, dont la projection est inclue dans Ii , est supérieur ou égal à un certain n.
ii) La taille de Ii est plus petite que d.
iii)
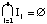
où n et d sont donnés comme entrées.
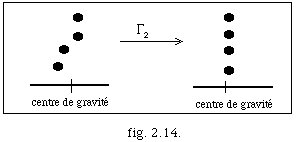
Après avoir trouvé I, on associe un point d'articulation à chaque Ii ; ce point est calculé comme le centre de gravité des événements dans l'intervalle.
Une deuxième transformation [[Gamma]]2 : sm -> sm est alors proposée. Elle consiste à déplacer les notes faisant partie d'un accord à son centre de gravité (fig. 2.14.).
2.2.2.6 Segmentation par motifs.
Voir chapitre 3.
Les résultats obtenus à partir des différentes méthodes de segmentation peuvent être aussi mélangés via des opérateurs logiques, pour produire ainsi une segmentation finale qui serve à l'étape suivante.
2.2.3 Extraction du tempo.
Étant donnés une segmentation en mesures et un ensemble de notes N, on procède à l'extraction du tempo. On note par Li la liste des durées de chaque segment produit de la segmentation en mesures et par d(S i) la durée du segment S i = efi - eoi.

On commence par calculer la pulsation, en utilisant un algorithme inspiré de l'algorithme de calcul de la fondamentale virtuelle d'un spectre discret exprimé comme une liste de fréquences (fig. 2.15.) . L'analogie utilisée fait correspondre la liste de fréquences à Li et la valeur de la fondamentale virtuelle à la valeur de la pulsation; ainsi la pulsation apparaît comme étant un grand commun diviseur approximatif des d(S i).
Trouver la pulsation est l'équivalent de la recherche de tempo, car la relation entre les deux est directe : le tempo est le nombre de pulsations par unité de temps .
ex : q = 60 signifie qu'il y a 60 noires dans une minute ; la noire (pulsation) dure donc une seconde.
Une première pulsation P1 est calculée par :
P1 = agcd (Li , tol1 ) , (fig. 2.16. pas 1)
où tol1 est le pourcentage maximal de déformation de la durée d'un
segment dans la recherche du gcd.
Après cela nous savons que d(S i)/P1 est le nombre d'itérations de P1 dans le segment Si. Remarquons que ce nombre d'itérations est un nombre réel dont la partie décimale dénote un résidu du segment.
Une deuxième pulsation P2 est alors calculée, ainsi :
P2 = agcd (Li /P1, tol2). (fig. 2.16. pas 2)
La tolérance tol2 signifie : au prix de quelle déformation de la durée d'un segment obtiendrait-on une nouvelle pulsation plus longue et informante sur la structure : cette nouvelle pulsation se subdiviserait en n pulsations de base, n étant couramment égal à 1, 2, ou 3.
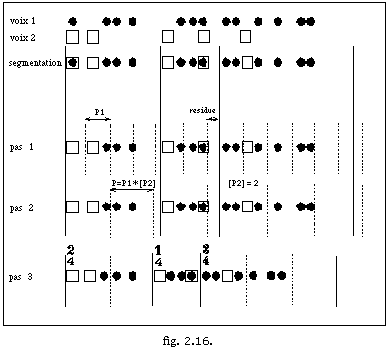
Nous calculons la valeur finale de la pulsation par :
P = P1* round (P2)
En général les combinaisons possibles de tol1 et tol2, dans un certain rang, convergent vers certains pôles d'attraction. Empiriquement nous avons remarqué que l'on a intérêt à régler tol1 assez bas (3% jusqu'à 15%) et tol2 doit au moins être égal à tol1 et le maximum de déformation autorisé ne dépasse pas en général 20 %.
Jusqu' ici nous avons associé à chaque segment Si , ki itérations de la pulsation P , ki étant un nombre réel ; cependant la notation musicale exige que le nombre des pulsations à l'intérieur d'une mesure soit un entier. La différence entre ki et round(ki) représente la différence entre la longueur du segment Si et la valeur de la mesure musicale.
Afin de préserver les proportions des durées à l'intérieur de chaque segment, on applique à chaque durée du segment Si un coefficient :
scal = round (ki) * P / d(Si)
Avec ce changement d'échelle on garde la structure avec pour résultat une troisième transformation [[Gamma]]3 : sm -> sm. A ce stade nous avons une division de la séquence en pulsations (fig. 2.16. pas 3) et on a trouvé une courbe de tempo constante T'' pour chaque pulsation.
2.2.4 Quantification.
Un moteur indépendant de quantification a été intégré à notre modèle. Ce moteur a comme entrées une liste de tempi, une liste de signatures de mesure et une liste de durées réelles destinées à être quantifiées. On se trouve face à une suite de pulsations contiguës avec des longueurs éventuellement différentes et un ensemble d'événements sonores appartenant à chaque pulsation.
Ce processus est réalisé indépendamment à l'intérieur de chaque pulsation, il permet ainsi l'interactivité avec l'utilisateur à différents niveaux dans la séquence. Les résultats, bons ou mauvais dépendent en grande partie du processus réalisé jusqu'à ce moment. C'est à dire, si une métrique et un tempo étaient donnés arbitrairement, les résultats seraient proches de ceux que donne un quantificateur industriel.
Le processus de réécriture à l'intérieur de chaque pulsation commence par la recherche d'un diviseur entier. On essaie exhaustivement les divisions possibles par des entiers dans un rang [min max], où le min est calculé en fonction de la durée minimale dans le pulsation et le max est fixé à 32. Chacun de ces diviseurs possibles définit une grille pour chaque pulsation. On doit maintenant trouver la "meilleure grille" relativement à certains critères.
On commence par bouger chaque attaque au point le plus proche dans la grille, et pour chaque grille on calcule une erreur relative à ce processus. Trois différents types d'erreur sont calculés :
-le premier est relatif à la somme des rapports cubiques des intervalles définis par l'attaque initiale et l'attaque de l'événement déplacé, pour tous les événements.
-le deuxième est une mesure conventionnelle de simplicité pour les différentes divisions ; notre définition de la simplicité est donnée par la liste suivante : 1,2,4,3,6,8,5,7, etc. où la division par 1 est la plus simple et chaque successeur dans la série incrémente la complexité.
-le troisième est la distance euclidienne entre les vraies attaques et les attaques déplacées.
Afin de choisir la division convenable les trois mesures d'erreurs sont combinées avec le processus suivant :
i) Un premier ensemble de grilles A est ordonné par rapport au premier critère.
ii) Un deuxième ensemble de grilles B s'ordonne selon le critère de simplicité.
iii) Ensuite les deux ensembles A et B sont filtrés par un ensemble de contraintes fournies par les paramètres max et forbid. Max spécifie le nombre maximum de divisions pour un pulsation ; forbid pour sa part interdit ou force la division par certains entiers[9] ; ainsi les grilles ne satisfaisant pas ces contraintes sont éliminées.
iv) Le choix final s'effectue en choisissant la grille la plus haute dans notre classement de chaque ensemble et en comparant pour chacune leurs valeurs respectives du critère de la distance euclidienne, modifiées par un facteur défini par le paramètre w appelé simplicité, lequel prend des valeurs entre 0 et 1; les valeurs proches de 0 favorisent la simplicité et les valeurs proches de 1 la précision. Pour le premier ensemble le facteur correspond à (1 - w ), alors que pour le deuxième on prend w. Ainsi des deux grilles on choisit celle dont la distance euclidienne affectée du scalaire w est la plus petite.
Si dans notre grille choisie deux attaques tombent sur la même division un des deux événements est éliminé par le processus de quantification, mais sa durée est conservée dans une structure spéciale qui va nous servir après pour noter cette note éliminée comme une appoggiature.
Les mesures d'erreur, qui en principe paraissent arbitraires, obéissent à un raisonnement musical : L'adoption d'une fonction cubique dans notre premier critère d'erreur, est du à la forme de cette fonction : elle tolère de petites erreurs et pénalise les grandes distorsions. L'utilisation de la distance euclidienne pour effectuer les choix entre les deux listes de solutions est convenable à ce niveau, étant donné que l'ordre défini par les deux premiers critères prévient le problème exposé au début du paragraphe.
On finit ce modèle par la reconstruction de la structure à partir des résultats obtenus pour chaque pulsation. Cette construction peut être vue comme la construction d'un arbre dont les feuilles représentent l'information rythmique d'une division en pulsations tandis que les noeuds supérieurs représentent l'information rythmique au niveau des mesures ou des ensembles de mesures.
Nous avons élaboré une technique de segmentation qui s'appuie sur la reconnaissance de motifs rythmiques. Le but est d'utiliser l'information rythmique fournie par la structure d'une séquence musicale. Les idées essentielles de cette technique ont été inspirées de [Fu 82]. Nous souhaitons favoriser avec cette méthode le critère d'optimisation dénommé apport d'information.
On peut grouper les techniques mathématiques, destinées à résoudre le problème de reconnaissance de motifs, en deux grandes approches : approche discriminante et approche syntactique.
- L'approche discriminante s'inspire de l'idée d'extraire un espace de caractéristiques d'un ensemble de motifs et de faire correspondre chaque motif à une classe. Les classes sont engendrées par une partition de l'espace de caractéristiques.
- Par ailleurs, l'idée essentielle de l'approche syntactique est d'exprimer un motif complexe en termes d'une composition hiérarchique de sous-motifs.
Nous avons axé plutôt notre recherche vers l'approche syntactique. En effet, il est de la première importance pour nous, de reconnaître non seulement le motif en général, mais encore de connaître certaines informations structurelles le concernant, c'est à dire les différentes opérations possibles de combinaison entre les sous-motifs. Néanmoins, il est clair que ces deux approches citées précédemment ne sont pas exclusives : ainsi en accord avec le problème posé, une combinaison de ces deux approches peut donner des résultats intéressants.
Notre système de reconnaissance de motifs peut se diviser en deux parties principales : analyse et reconnaissance.
Il s'agit pour la partie analyse :
- Du choix des motifs primitifs, ceux-ci étant les unités minima pour la construction de sous-motifs.
- De l'inférence d'une grammaire, qui exprime la façon selon laquelle ces motifs primitifs peuvent se combiner afin de former des sous-motifs.
Quant à la partie de reconnaissance, elle est composée de :
- Un processus de prétraitement, il s'agit de donner une représentation approchée et compressée de notre séquence d'entrée.
- Un processus nommé segmentation en motifs primitifs, il se charge de la reconnaissance des motifs primitifs.
- Une reconnaissance de motifs, afin de repérer à l'intérieur de la séquence les motifs syntactiquement corrects par rapport à la grammaire donnée.
Dans notre modèle nous proposons deux sortes de segmentation par motifs :
- l'identification de motifs spécifiés a priori (3.1).
- la recherche d'une segmentation optimale par motifs (3.3).
3.1. Identification de motifs spécifiés a priori.
Cette méthode permet de repérer des motifs dans une séquence musicale appartenant à une classe, déterminée par une grammaire donnée comme entrée du système.
3.1.2. Prétraitement.
L'objectif de cette étape est de transformer notre séquence d'entrée en une représentation plus compacte, sans perdre l'information essentielle à tout le processus. Aussi l'on filtre l'information indésirable et l'on met en relief certains points d'intérêt.
Supposons que notre motif d'entrée soit donné par la liste polyphonique de durées suivante, exprimée en secondes :
( (0.30 0.60 0.30 0.30) (0.60 0.60 0.30) (0.30 0.35 0.30 0.30) ) ( voir fig. 3.1 ).
La nouvelle représentation de la séquence sera :
( (0.0 0.0 3) (0.83 -25.0 5) (4.0 20.0 6) (0.8 -20.0 7)
(4.0 20.0 8) (0.80 -20.0 9) (4.0 20.0 11) )
où chaque élément (p d i) de la liste représente un événement, avec i la position dans la liste polyphonique mise à plat, p la différence en pourcentage de la durée de l'événement par rapport à l'événement immédiatement antérieur, et d la même différence mais exprimée en secondes. Notons qu'à l'intérieur d'un accord si deux événements ont la même attaque l'un de deux est éliminé, alors que les événements dont la différence des durées est petite seront mis en relief.
3.1.2. Choix de motifs primitifs.
Les motifs primitifs doivent être choisis de telle manière qu'ils soient des objets simples, avec peu d'information structurelle et surtout reconnaissables de façon évidente. Nous définissons quatre classes de motifs primitifs selon la différence des durées :
i) La classe > : Si la durée de l'événement est plus grande que celle de l'événement précédent.
ii) La classe < : Si la durée de l'événement est plus petite que celle de l'événement précédent.
iii) La classe = : Si la durée de l'événement est égale à celle de l'événement précédent.
iv) La classe j : Cette classe est une classe spéciale que nous appelons joker. Le but de ce traitement est la prise en compte des distorsions possibles de notre séquence d'entrée.
Le problème de distorsion de motifs présente deux ambiguïtés essentielles : ou notre motif n'est pas accepté par une grammaire donnée, ou un motif appartenant à plusieurs classes dans l'espace de décision est le même. Entre les différentes propositions concernant le traitement de distorsion de motifs, nous avons choisi l'approximation : Comme son nom l'indique, il s'agit d'approcher au mieux les données, pendant les étapes de prétraitement et de sélection de motifs primitifs. Pour cela nous utilisons deux paramètres d'entrée, err% et errsec, qui donnent respectivement une marge d'erreur par pourcentage et par secondes. Ainsi lorsque la différence entre les durées des deux événements tombe dans l'un des deux intervalles définis par ces paramètres, le motif primitif sera de type j.
3.1.3. Segmentation en primitifs.
En général et en raison de la mince information structurelle que possèdent les motifs primitifs, on utilise une technique d'approche discriminante pour leur reconnaissance. Cette reconnaissance est une application de l'espace des événements représentés par (p, d, i) dans l'espace de décision constitué des quatre classes : >,< ,=, j.
En suivant l'exemple proposé au paragraphe précédent, avec err% = 10% et errsec = 0.05 sec. la représentation des motifs primitifs sera :
( (j 3) (< 5) (> 6) (< 7) (> 8) (< 9) (> 11) )
où la première coordonnée représente la classe de motifs primitifs et la deuxième, la position de l'événement dans la liste initiale.
A ce stade, et en prenant la concaténation comme opération unique entre nos motifs primitifs, notre entrée peut être représentée par la séquence suivante :
"j < > < > < >"
Remarquons que notre langage est un cas simple et particulier appelé langage en séquences (string language).
3.1.4. Inférence d'une grammaire.
La caractéristique de cette méthode - qui la rend simple - est de connaître auparavant la grammaire que nous allons utiliser pour la reconnaissance d'une classe spéciale de motifs. Nous avons choisi les expressions régulières comme moyen de représenter cette grammaire. Les exemples suivants mettent en lumière la sémantique :
( < > > ) Une note courte suivie de deux notes longues.
( > +) Un rallentendo
( ((< +) | (> +))*) Un accelerando ou un rallentendo zéro ou plusieurs fois.
3.1.5. Reconnaissance de motifs.
Étant donnée notre représentation des classes de motifs par des expressions régulières, il est simple d'effectuer la reconnaissance de ceux-ci en prenant appui sur la théorie des automates finis. L'idée est de placer un automate pour chacun des 3 terminaux de notre langage (> , < , =); chaque automate reconnaît en outre le terminal j. De même pour chacune des opérations définies entre les terminaux (concaténation, plus, étoile) , nous définissons l'opération correspondante entre les différents automates qui reconnaissent chaque terminal. Les différents motifs que l'on peut rencontrer à l'intérieur de notre séquence d'entrée sont disjoints, c'est à dire qu'une fois que nous avons trouvé un motif en position i, de longueur j, nous poursuivons la recherche à partir de i+ j et non à partir de i + 1. L'explication de cette décision est que chaque motif va être associé à une mesure, et parler de mesures non disjoints n'aurait aucun sens musicalement. Pour détecter des motifs à l'intérieur d'un autre motif, nous offrons la possibilité d'imposer des contraintes aux motifs appartenants à la classe définie par l'expression régulière d'entrée. Deux types de contraintes sont proposés : la première sur la longueur de motif exprimée en nombre d'éléments, et où nous pouvons imposer un nombre minimum et maximum de notes à notre motif. La deuxième concerne aussi la longueur du motif, mais cette fois-ci la longueur est exprimée en secondes.
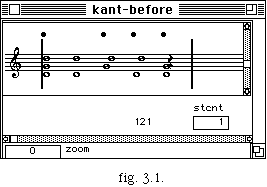
La figure 3.1 montre la segmentation sur l'entrée ((= +) | (< >)) pour la séquence qui nous a servi d'exemple dans ce paragraphe.
3.2. Recherche d'une segmentation optimale par motifs.
A la différence de la méthode précédente, ici, nous ne connaissons pas à l'avance la classe de motifs que nous recherchons. Ce modèle se base donc sur la définition d'un critère d'optimisation, en classant les combinaisons possibles de motifs primitifs selon ce critère.
3.2.1. Prétraitement.
Cette étape corresponde à l'application des étapes de prétraitement et segmentation en motifs primitifs exposées au paragraphe 3.1.
3.2.2 Sélection de motifs primitifs.
Pour cette méthode les motifs primitifs définis possèdent une information structurelle encore simple mais de plus haut niveau que ceux définis précédemment. Trois classes de motif primitifs sont définis :
i) La classe a (accelerando) définie par <* j* <*.
ii) La classe r (rallentendo) définie par >* j* >*.
iii) La classe e (notes répétées) définie par =* j* =*.
3.2.3. Segmentation en motifs primitifs.
Notons que les jokers peuvent appartenir à toutes les classes. Ceci implique la nécessité d'un traitement d'erreur afin d'éliminer les ambiguïtés possibles.
La notation et certaines définitions sont données avant l'exposition de notre méthode de traitement d'erreur.
i) Nous définissons une grammaire G par :
VT = { j, >, <, = }
VN = { a', r', e' }
P = a' -> <+
r' -> >+
e' -> =+
ii) Nous prenons tout d'abord deux cas de transformations sur les séquences
- Substitution : w1aw2 [[arrowvertex]][[arrowhorizex]] w1bw2 a,b [[propersubset]] VT a != b et w1,w2 [[propersubset]] VN
- Suppression : w1aw2 [[arrowvertex]][[arrowhorizex]] w1w2 a [[propersubset]] VT et w1,w2 [[propersubset]] VN.
Chacune de ces transformations a associé une fonction de coût :
- Sub (a,b) comme le coût de substituer a par b dans w1aw2.
- Sup (a) comme le coût d'effacer a de w1aw2.
iii) Nous définissons ensuite la distance entre deux séquences X et Y par :
d(X,Y) = min { |T| }
j
où T est une séquence de transformations pour aller de X à Y et |T| est la somme
des différents coûts associés à chaque transformation.
iv) Rappelons que chaque terminal est associé à un événement sonore représenté par
(p,d,i). Nous définissons ainsi les fonctions :
q(x) = (p,d,i) où x [[propersubset]] VT et (p,d,i) représente l'événement associé à x.
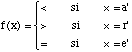
Une simple application nous permet de représenter notre séquence d'entrée par une séquence du langage défini par la grammaire G. L'élimination des terminaux j permet d'obtenir une segmentation en motifs primitifs, en accord avec les classes données au paragraphe 3.2.2.
Nous observons deux cas différents de distorsion :
- w1jw2 avec w1,w2 [[propersubset]] VN
- w1Jw2 avec w1,w2 [[propersubset]] VN et J = jj+.
Dans le premier cas :
Si w1 = w2 une transformation par suppression définira la meilleure solution. Ainsi w1jw2 sera transformé en w1.
Si w1 != w2 nous calculons d(w1j, w1f(w1)) et d(jw2, f(w2)w2).
La séquence w1jw2 sera remplacée par w1w2 et j sera concatenée avec le wi qui présente la distance minima. Notre définition de distance est donnée par :
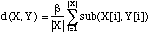
avec
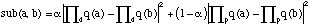
Le paramètre [[alpha]] prend des valeurs entre 0 et 1; les valeurs proches de 0 favorisent l'erreur par pourcentage et les valeurs proches de 1 l'erreur euclidienne.
Le paramètre [[beta]] est relatif à la longueur de la séquence, par exemple un valeur de [[beta]] grande tend à associer j avec max(|w1| ,|w2|).
Dans le deuxième cas :
Nous calculons les distances,
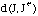
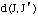
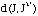
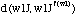
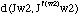
où
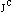 est une séquence résultat de la substitution de chaque j de J
par l'élément minimum de la classe C.
est une séquence résultat de la substitution de chaque j de J
par l'élément minimum de la classe C.
Nous transformons J en accord avec la distance minimum trouvée.
Il faut remarquer que nous ne prenons pas en compte la possibilité de distribuer J entre w1 et w2, c'est à dire nous ne permettons pas l'association d'un point d'articulation à l'intérieur de J. Cette séquence, étant données ses caractéristiques est perçue comme une unité.
Le séquence, produit de l'application des deux cas de transformation expliqués ci-dessus, est soumise à un système de réécriture afin de donner la segmentation définitive en motifs primitifs. Les règles de réécriture utilisées sont :
< -> a
> -> r
= -> e
a'a -> a
r'r -> r
e'e -> e
aa' -> a
rr' -> r
ee' -> e
3.2.4. Inférence des grammaires.
Les grammaires que nous allons analyser présentent le même ensemble de terminaux :
VT ={a,r,e}
Une règle de production P est assignée à chaque grammaire. Chaque grammaire correspond à l'une des possibles combinaisons entre trois terminaux maximum, par exemple :
P1 : S -> ara
P2 : S -> rae
P3 : S -> a , etc...
Avec trois terminaux comme maximum, nous obtenons 21 grammaires différentes ; chacune de celles-ci détermine une classe de motif différente. Le choix du maximum de terminaux est optionnel, cependant musicalement la combinaison d'un grand nombre de terminaux est inusitée.
3.2.5. Identification de motifs.
Afin de calculer une solution produit de la combinaisons des motifs primitifs, nous effectuerons une reconnaissance de motifs pour chacune des grammaires données, selon la méthode exposée au paragraphe 3.1.
Les solutions proposées par ses reconnaissances sont ordonnées d'après trois critères :
i) Nombre maximum d'occurrences du motif spécifié par chaque grammaire, à l'intérieur de la séquence.
ii) Pour chaque solution, nous calculons le nombre maximum d'occurrences du
motif spécifié par la grammaire
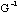 ,
à l'intérieur de la séquence complément[10] de la solution.
,
à l'intérieur de la séquence complément[10] de la solution.
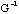 est la grammaire qui correspond à l'inversion de la partie droite de la
règle de production de G, par exemple :
est la grammaire qui correspond à l'inversion de la partie droite de la
règle de production de G, par exemple :
si
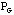 : S -> rda alors
: S -> rda alors
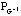 : S -> dr.
: S -> dr.
Il est clair qu'au moyen de ce critère nous cherchons à favoriser la recherche de structures de miroir.
iii) Une bonne solution en accord avec les deux critères antérieurs peut contenir dans son complément des structures qui ne donnent pas satisfaction aux contraintes, faisant référence à la longueur du segment. Nous ordonnons les solutions par rapport au nombre de structures indésirables dans leur complément.
Enfin l'on donne un poids à chacun de ces critères. En accord avec cette pondération, nous ordonnons une liste définitive et nous présentons les solutions dans l'ordre, en offrant une possibilité de choix et de combinaisons entre elles.
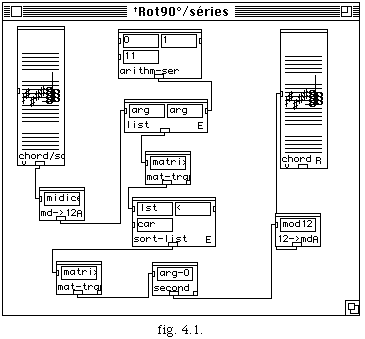
Une implémentation de notre modèle existe comme une nouvelle boîte dans l'environnement de programmation PatchWork. Le choix de PatchWork comme environnement de programmation a pour but l'intégration, dans cet environnement d'outils d'aide à la composition. Nous comptons intégrer notre quantificateur rythmique au dit environnement de précomposition, afin de tirer parti de son interaction avec les différents outils réalisés, ainsi qu'avec de futures implémentations.
Avant de donner une description de cette implémentation, nous présenterons sommairement PatchWork, pour plus de détail voir, [Rueda 93] , [LRD 93].
4.1. L'environnement de programmation PATCHWORK.
PatchWork est un environnement graphique interactif de composition assistée par ordinateur (CAO), ayant pour objectif d'aider le compositeur à créer, représenter, manipuler le matériau musical.
Développé en Common Lisp (CLOS) sur Macintosh, il est à l'origine principalement destiné à un usage de génération, de manipulation, et d'édition de structures musicales pour la production de matériau précompositionnel en musique instrumentale. Le choix de Lisp pour l'implémentation de PatchWork fut fait en pensant aux avantages que ce langage présente, en autres :
i. Un fort degré d'interactivité, permettant à l'utilisateur de définir ses propres fonctions
d'une manière simple.
ii. Une utilisation efficace des listes, qui correspondent à la structure standard utilisée par la plupart des dispositifs de communication.
iii. La possibilité d'un langage orienté objet CLOS, ce qui est cohérent avec l'idée de hiérarchie présentée par les différents objets musicaux. Cela permet facilement l'application d'opérateurs à différents niveaux i.e. transposition de notes, d'accords, de lignes musicales, etc..
iv. Lisp est un langage interprété.
v. Lisp presente une forte garantie formelle : le [[lambda]]-calcul.
- Le concept de patch graphique.
Il s'agit d'une procédure d'exécution programmée de manière graphique, reliant entre eux des objets (programmes), représentés à l'écran par des boîtes munies d'entrées et de sorties. Le tracé d'un réseau de relations fonctionnelles entre ces objets, définit un comportement correspondant à une application particulière de génération, de transformation, ou d'édition de données musicales. La figure 3.1 montre un exemple de Patch.
L'évaluation d'une boîte B d'arité n, peut être vue comme :
v(B) = Bf ( v(B1), v(B2),... v(Bn))
Où Bf est la fonction assignée à la boîte B.
-Les boîtes PatchWork.
La boîte est l'unité de base de PatchWork ; elle comporte un nombre variable d'entrées, une sortie, et une fonction dont le code est aisément accessible et modifiable.
Les boîtes peuvent être de divers types :
- Lisp (fonctions du langage Lisp) ;
- Calculs (opérations arithmétiques, logiques, ensemblistes) ;
- Conversions (entre valeurs numériques et symboliques);
- Génération de structures musicales (interpolation d'accords ou de motifs, construction de séries et de spectres, etc.) ;
- Manipulation de structures musicales (filtrages fonctionnels ou par contraintes) ;
- Midi (réception et envoi de données vers des synthétiseurs externes avec possibilités d'échelles en micro-intervalles) ;
- Contrôle de la synthèse (pilotage des programmes de synthèse Csound et Chant).
- Édition de courbes, et de notation musicale traditionnelle , ces boîtes en particulier gardent l'état du calcul à l'instant où elles sont évaluées.
-Sémantique.
Un Patch dans PatchWork peut être vu comme un graphe acyclique P = (B, E, C, F, O), où B est l'ensemble de sommets appelé boîtes; E est l'ensemble de sommets appelé entrées; C est un ensemble d'arcs dirigés appelés connections; F est un ensemble de sommets étiquetés appelé values et O est un ensemble d'arcs appelé ordering. C est un sous-ensemble de BxB -> BxE.
-Conception et programmation de PatchWork :
Mikael Laurson, Camilo Rueda, Jacques Duthen
4.2 Kant-PatchWork.
Kant a été implémenté comme une boîte d'édition musicale dans PatchWork. Cette boîte a comme entrée une liste de listes, où chaque sous liste contient les durées d'une voix déterminée par sa position dans la liste. La sortie est un objet qui représente une liste de mesures, laquelle peut éventuellement être connectée à l'entrée d'un éditeur musical polyrythmique (rtm-poli).
En nous basant sur l'exemple suivant (fig. 4.2), nous expliquerons le fonctionnement de Kant-PatchWork .

Les valeurs des durées sont exprimées en centièmes de seconde et les valeurs négatives représentent des silences.
Après avoir évalué la boîte Kant, on peut réaliser le processus de quantification des données; on ouvre alors l'éditeur et on obtient ainsi la représentation suivante des données (fig. 4.3).
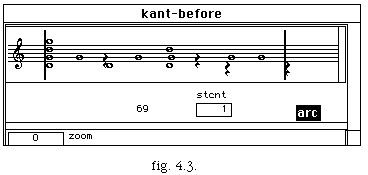
Chaque voix est représentée par un ensemble d'événements (o) sur une ligne dans la partition. Chaque ligne de voix a un position de bas en haut, selon sa position dans la liste. Les symboles o montrent le début de chaque événement et sa durée est marquée par le début de l'événement suivant.
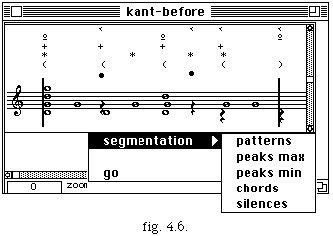
Trois menus arc mes et qua sont proposés, correspondant respectivement à la segmentation en archimesures, la segmentation en mesures et à la quantification ; l'extraction du tempo se fait à l'intérieur du menu mes.
4.2.1 Segmentation en archimesures.
Le menu arc correspond à l'étape de segmentation en archimesures. Pour l'instant, quatre méthodes sont proposées pour faire la segmentation. On associe à chaque méthode un symbole :
[[Delta]] pour la segmentation manuelle,
[] pour simple lissage, (smooth)
x pour la segmentation par densités (density)
= pour le segmentation avec accelerando (accel).
Le symbole est positionné sur la note où l'archimesure commence (fig. 4.4).
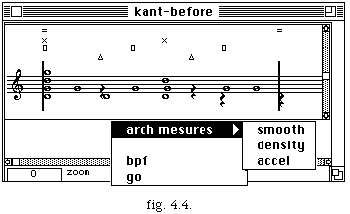
Les différentes méthodes peuvent être combinées via des opérations logiques ( union , intersection, différence) en donnant ainsi origine à une segmentation finale qui sera validée par l'option go.
Une représentation graphique de numéro d'événement / durée d'événement est fournie par l'option bpf. Ce graphique donne une vision générale des différents points d'articulation de la séquence.
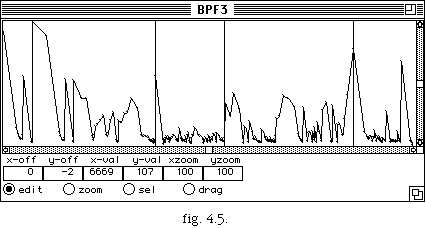
Dans cet exemple on voit qu'un mouvement avec un tempo lent est suivi d'un tempo rapide après un autre tempo lent et finalement un petit rallentendo.
4.2.2 Segmentation en mesures et extraction du tempo.
Après avoir segmenté en archimesures, nous procédons à la segmentation en mesures sur l'ensemble des archimesures ou sur une archimesure spécialement sélectionnée. Ce processus, ainsi que l'extraction du tempo, sont fournis par des options dans le menu mes.
Cinq méthodes sont, pour l'instant proposées et un symbole est associé à chacune (fig. 4.5) :
* pour la méthode manuelle
* pour les notes longues (peaks max)
+ pour les petites notes (peaks min)
[[ordmasculine]] pour les accords (chords)
< pour les silences (silences)
( pour les motifs (patterns).
De la même façon que pour les archimesures les différentes méthodes peuvent être combinées entre elles via des opérateurs logiques. La segmentation en mesures étant définie, on continue avec l'extraction du tempo. En utilisant l'option go, le dialogue suivant s'affiche:
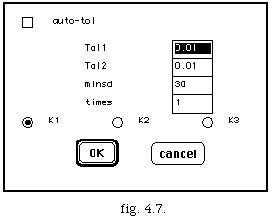
Les paramètres tol1 et tol2 sont les valeurs des tolérances de notre algorithme acgd; minsd filtre les segments dont la durée est inférieure à la durée spécifiée; times multiplie ou divise le tempo selon la valeur donnée. Cette opération déforme notre algorithme de acgd car le fait de multiplier ou de diviser la valeur de la pulsation par un facteur introduit des pourcentages d'erreur différents pour chaque mesure ; une opération de "réglage de paramètres" est proposée par le bouton auto-tol. Cette opération calcule les combinaisons différentes de tol1 et tol2 entre un certain rang. On note que les valeurs des tempi convergent vers des pôles d'attraction, ainsi la liste de tempi proposée est d'habitude petite.
Après avoir sélectionné le tempo, on continue avec le changement d'échelle des durées des notes et la création de mesures. Les durées mis à l'échelle et la pulsation sont affichées après cette étape (fig. 4.8.).
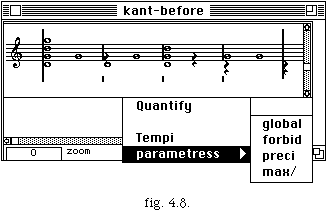
Nous sommes prêts pour la dernière étape de notre processus.
4.2.3 Quantification.
L'option quantify est chargée d'exécuter la quantification telle que nous l'avons expliquée dans le chapitre 1.
Le réglage des paramètres globaux ou par défaut est fournie par l'option globals; de la même façon le réglage des paramètres pour chaque mesure et aussi pour chaque pulsation dans une mesure est fourni par l'option paramètres. Par exemple pour le paramètre forbid la syntaxe est la suivante :
Une liste simple , comme ( 9 7 6), ne permet pas, au niveau global, des divisions par 9, 7 ou 6 . L'introduction de sous listes au premier niveau indique un contrôle sur les mesures : par exemple (() (5 6) ()) indique :
-deuxième mesure
divisions par 5 et 6 interdites,
-première et troisième mesures
pas de contrainte.
Un deuxième niveau de sous listes nous permet de contrôler les subdivisions dans la pulsation, par exemple la liste (() (() (! 5) ( 8 7) ()) ) indique :
-première mesure
pas de contrainte.
-deuxième mesure
première et quatrième pulsations: pas de contrainte.
troisième pulsation: subdivisions en 8 et en 7 interdits.
Le symbole ! impose la subdivision en 5 dans la deuxième pulsation de la troisième mesure. Cet opérateur peut être utilisé aussi bien pour les mesures que pour les pulsations.
Afin de faciliter la construction de ces listes, l'utilisateur a la possibilité d'éditer chaque mesure en cliquant sur la barre de mesure.
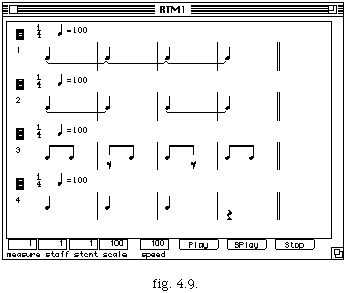
Une fois les paramètres réglés, on lance le processus de quantification : le résultat est exposé comme dans la figure 4.9.
Plusieurs solutions concernant les différents choix dans le processus peuvent être obtenues ; cela nous permet de faire une comparaison entre elles pour prendre des décisions.
Le résultat final est aussi la sortie de la boîte Kant et en général elle est connectée avec des boîtes d'édition rythmique.
Après cette présentation de notre modèle, nous espérons avoir exprimé avec clarté notre conception de la quantification rythmique, qui se situe bien au-delà du traitement purement mathématiquement qui lui a été donné. L'un de nos apports principaux a été la remise en question de la définition d'une "bonne quantification". En effet, généralement, celle-ci prenait en compte uniquement la fidélité à la réalité. Pour nous, la simplicité de notation et l'information structurelle livrée par la transcription ont aussi une grande importance. De plus la possibilité est offerte à l'utilisateur de pourvoir le système de l'information nécessaire, afin que celui-ci favorise ou non chacun des critères énumérés.
Une autre apport intéressant a été la différenciation entre quantification et transcription. Notre modèle peut prendre place dans le processus compositionel grâce aux différentes transformations, appliquées aux données tout au long de la quantification. De même la quantification, telle que nous la voyons, doit jouer un rôle dans le domaine de l'analyse. Notre nouvelle méthode de segmentation par motifs permet l'exécution de calculs et l'identification d'objets à l'intérieur d'une séquence, de façon automatique ou interactive.
Notre quantificateur divise clairement le processus en niveaux interactifs et modulaires. Ainsi les solutions et possibles problèmes à chaque niveau, deviennent plus spécifiques. De même les opérations appliquées à un certain niveau peuvent être mises à profit pour un autre niveau, grâce à la structuration hiérarchique que nous avons définie.
Le problème de la quantification rythmique est un problème difficile en soi. Ce stage est loin de l'épuiser. Néanmoins les exemples musicaux quantifiés donnent de bonnes solutions du point de vue musical. Les résultats de ce projet seront présentés par l'Ircam à l'International Computer Music Conference (ICMC) qui aura lieu mi-septembre 1994.
Les perspectives immédiates de notre projet impliquent :
-L'augmentation de notre espace de caractéristiques d'un événement sonore, en incluant hauteur et intensité. Ces nouveaux espaces devraient augmenter aussi notre système de reconnaissance de motifs.
-Créer et appliquer différentes opérations sur la courbe de tempo, une fois quelle sera trouvée. Une relation hiérarchique des archimesures -plus que la simple relation de concaténation que nous avons définie- serait fort utile, étant donné que les opérateurs peuvent être hérités par des archimesures à l'intérieur d'une archimesure principale. Nous espérons de même pouvoir effectuer différentes combinaisons de la courbe de tempo à l'intérieur d'une archimesure.
-Nous souhaitons aussi tester des nouvelles méthodes de segmentation, nous tenterons de faire une analogie avec les différents domaines où la segmentation joue un rôle important i.e. la parole, l'image, etc...
-Il est évident que de grandes améliorations vont être faites à notre jeune système de segmentation par motifs.
-Une structure hiérarchique permettant le contrôle à l'intérieur de chaque pulsation, mesure ou globalement, devra être implementée pour chacun des différents paramètres.
L'implémentation de notre modèle, ainsi que l'article [AAFR 94] sont disponibles au titre de matériel en développement ( assayag@ircam.fr ).
accelerando Terme italien ; littéralement : en accélérant. Terme d'exécution musicale indiquant que le mouvement (ou tempo) doit devenir progressivement plus rapide.
appoggiature Définition originale : ornement expressif introduisant passagèrement une dissonance et ayant pour effet de renforcer le temps sur lequel il se place. L'histoire des variations de l'appoggiature est très complexe.
Dans le projet Kant, appoggiature est pris au sens large : groupe de notes très proches que l'on transforme en ornementation tombant sur le temps d'attaque.
archimesure Notion propre au projet Kant. Intervalle entre deux points d'articulation "forts" : coïncidence importante en nombre de voix, points d'articulation donnés par le compositeur, autres critères à déterminer. Une archi-mesure comme son nom le suggère couvre une ou plusieurs mesures.
attaque L'attaque d'un son est le passage transitoire du début de l'excitation du corps vibrant au régime établi. Elle constitue la tête du son, véhicule une grande information et définit presque à elle seule l'instrument dont elle émane. D'un point de vue musical, l'attaque est la manière d'émettre les sons de la voix, de mettre en vibration les cordes ou la colonne d'air et d'actionner les touches d'un instrument.
durée Temps pendant lequel un son, un silence doit être maintenu. La durée s'exprime par une ou plusieurs figures de notes ou de silences.
événement sonore Un événement sonore peut être un objet musical simple ou complexe selon les besoins du compositeur. Par simplification de langage, on emploie souvent dans ce rapport ce terme ou celui de note.
hauteur La hauteur d'un son est liée à sa fréquence, c.-à-d. au nombre de vibrations par seconde du corps sonore. En fait, l'expérience montre que la sensation de hauteur donnée par des sons de fréquence égale dépend encore de leur timbre, de leur intensité, de leur hauteur absolue, du contexte où ils se trouvent, etc...
liaison Du point de vue rythmique : ligne arquée placée au-dessous de deux notes. Une liaison réunissant la tête de deux notes consécutives de même hauteur indique l'addition en une seule note des deux valeurs de durée.
mesure En son sens le plus général, la mesure désigne une manière d'être du rythme, à savoir l'organisation selon des proportions rationnelles de ses durées consécutives. Si le rythme libre, non mesuré, a pratiquement disparu en Occident (du moins jusqu'à une date très récente) en raison du développement de la polyphonie, il n'en continue pas moins à jouer un rôle essentiel pour certaines musiques traditionnelles ; ainsi les préludes appelés "âlâpâ" en Inde ou "taqsim" au Proche-Orient observent une rythmique spontanée.
En sons sens usuel, celui que lui donne la théorie classique, la mesure relève d'un agencement rythmique plus rigoureux encore, défini avant tout par ses périodicités et ses symétries : celles-ci sont concrétisées graphiquement dès le XVIIè siècle par les barres de mesures réalisant un compartimentage du flux rythmique en subdivisions de durées égales ou "isochrones" : les mesures.
Par extension, on donne également ce nom à la portion de musique comprise entre deux barres consécutives.
métrique Le terme s'emploie en musique, par exemple pour définir le groupement d'unités de temps en mesures.
monodie Désigne une musique qui s'exprime en une succession ordonnée de sons isolés et qui, par sa dimension exclusivement linéaire et mélodique, s'oppose à la polyphonie.
notes Signes conventionnels de forme et de nom variables suivant les systèmes de notation, servant à exprimer graphiquement les sons, d'une part la hauteur par leur position sur la portée, d'autre part la durée par leur forme.
notation Ensemble des signes conventionnels qui servent à fixer par écrit les sons musicaux et leur interprétation. L'usage de la notation caractérise la musique savante occidentale depuis l'Antiquité grecque et, par la même, une certaine conception de l'oeuvre musicale comme un processus achevé, nettement délimité dans le temps, ayant un commencement, un milieu et une fin, où le geste créateur appartient à l'histoire et se trouve objectivé, donc soumis après coup à l'analyse et à la réflexion. La notation est inséparable des notions d'écriture, de forme et d'architecture, d'où son importance dans l'incessante évolution de la musique occidentale.
polyphonie Superposition de deux ou plusieurs lignes mélodiques simultanées formant un ensemble homogène tout en conservant chacune un intérêt propre. La polyphonie réunit deux dimensions complémentaires du langage musical : horizontalité de la mélodie et verticalité de l'harmonie. Le dosage mutuel de ces deux composantes donne naissance à des styles variés qui, en Occident, se sont succédés dans le sens d'une emprise croissante du verticalisme harmonique, du moins jusqu'au début du XXè siècle. On peut donc opposer la notion de polyphonie à la fois à celle de monodie et à celle d'homophonie.
pulsation Voir temps
quintolet Groupe de cinq notes égales qui s'exécutent dans le même temps que quatre notes semblables. On le représente par le chiffre 5 placé au-dessus ou au dessous du groupe.
rallentendo Terme italien ; littéralement : en ralentissant. Terme d'exécution musicale indiquant qu'il faut progressivement ralentir le mouvement (ou tempo).
rythme Le rythme est l'être temporel de la musique et lui confère l'unité temporelle : ce par quoi la musique, quoique discursive, est une. Il est la cohérence continue qui transcende les instants dans lesquels l'analyse peut décomposer la musique : il la fait exister.
Le rythme comporte l'articulation des actes musicaux successifs ; il est donc la manière d'être ou la forme temporelle de la musique, le mode particulier selon lequel celle-ci réalise son existence dans le temps.
Au sens étroit, le rythme est l'ordre et la proportion des durées, relativement longues ou brèves. Au sens large, il est l'ensemble du mouvement musical.
tempo Sert à désigner le mouvement dans lequel s'exécute une pièce musicale qui prend appui sur les cadres fixes de la mesure, lorsque celle-ci fait défaut, sur des repères mélodiques, harmoniques, rythmiques ou dynamiques (préludes non mesurés).
Dès que se dégage la notion d'unité de temps (voir temps), c'est de la valeur de celle-ci que va dépendre le tempo. Il peut être indiqué par une indication expressive (ex : andante, allegro ...) ou par le temps métronomique.
ex : q = 60 signifie qu'il y a 60 noires dans une minute ; la noire dure donc une seconde.
Dans une mesure à 4/4, le temps = la noire d'où le temps (ou pulsation) a une durée de une seconde.
Le temps métronomique indiqué au début d'une page musicale ne constitue qu'un tempo moyen à l'intérieur duquel peuvent intervenir accelerando ou rubato.
temps (beat en anglais). La pulsation basique sous-tendant la musique mesurée c.-à-d. l'unité temporelle d'une composition. Le groupement de temps forts et de temps faibles en de plus larges unités appelées mesures constitue la métrique. Une mesure se subdivise donc en temps d'égale durée.
ex : une mesure à 3/8 signifie qu'il y a 3 temps dans chaque mesure et que le temps a une durée égale à la croche.
Dans ce rapport, on emploie indifféremment le terme de temps ou pulsation.
voix Chacune des parties d'un ensemble polyphonique vocal (choeur) ou instrumental (fantaisie, "ricercare", fugue, ...).
[AAFR 94] Kant : a Critique of Pure Quantification, Agon C., Assayag G., FinebergJ., Rueda C. , ICMC 94. Aarhus, 1994.
[AR 93] G. Assayag, C. Rueda. The Music Representation Project at IRCAM. Proceedings of the ICMC, Tokyo, 1993.
[Brown 93] BROWN J.C., Determination of the meter of musical scores by autocorrelation. J.Acoust.Soc.Am. 94. 1953-1957. 1993.
[Court 76] COURT R., Essai sur les fondements anthropologiques de l'art, Ed. Klinsksieck, 1976.
[DH 92] DESAIN P , HONING H. , The quantization problem : Traditional and connectionist approaches, dans Music, Mind and Machine 1992.
[Emery 75] EMERY Eric, Temps et Musique, L'Age d'Homme 1975.
[Fu 82] FU King Sun, Syntactic Pattern Recognition and Applications, Prentice Hall, 1982.
[Lester 86] LESTER Joel, The rythms of tonal music, Southern Illinois University press 1986.
[LRD 93] M. Laurson, C. Rueda, J. Duthen. The Patchwork Reference Manual, IRCAM, 1993.
[MZ 94] MAZZOLA G. et ZAHORKA O. Tempo Curves Revisited : Hierarchies of performance Fields, Computre Music Journal Vol 18, Number 1, Spring 1994.
[Paczynski 88] PACZYNSKI Rythme et geste , Zurfkuh, 1988.
[Rueda 93] RUEDA C., PatchWork Architecture, IRCAM 1993.
[Steel 90] STEELE, G. L.,Jr. Common Lisp The language, second Edition, Digital , 1990.
[Turchetti 82] TURCHETTI M., Adorno : philosophie de la musique et historicité, Revue d'esthétique nouvelle serie Ndeg. 4 , Privat 1982.
[Stern 90] STERN J., Fondements Mathematiques de L'Informatique, McGraw - Hill , 1990.
[Verriere 93] VERIERE V., Kant Quantification Rythmique Structurée, Stage de DESS d'Intelligence Artificielle PARIS VI, 1993.
[Viora 82] VIORA J. L., Ma Notation Musicale, Musique presente Ndeg. 4, Privat 1982.
[Witt 93] WITTGENSTEIN L., Tractatus Logico-Philosophicus, Ed. Gallimard , Paris, 1993.