Dans ce chapitre nous detaillons le travail fait pendant le stage. Nous expliquons les techniques d'analyse utilisees, mais egalement les manieres d'interagir avec elles a travers l'interface graphique. Nous montrons comment nous visualisons les resultats et comment on peut les manipuler ainsi que les modalites d'entree des parametres de controle.
Pour la description nous proposons deux techniques principales. Dans la premiere nous modelisons le son comme une suite d'unites sonores distinctes. Chaque unite sonore commence a la fin de l'unite precedente. Les temps de debut et les temps de fin des unites sont determines et pour chaque unite une representation en forme d'accord est donnee. Nous appelons cette maniere de decrire la representation en suite d'accords.
La deuxieme technique fait une analyse plus detaillee du contenu frequentiel dans le sonagramme. Nous allons chercher les partiels qui sont presents dans le son et nous attacher a en decrire le deploiement temporel. Nous appelons cette analyse le suivi de partiels. Dans ce dernier cas, la notion d'evenement devient plus lache (c'est particulierement vrai s'agissant de trames sonores tres continues). D'une certaine maniere, c'est chaque partiel qui devient un evenement.
Les deux demarches partent d'une representation intermediaire du son: le sonagramme.
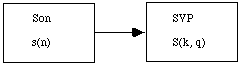
La base de toute les descriptions et analyses que nous proposons est une representation tridimensionnelle du son dans un espace temps, frequence et amplitude: le sonagramme. L'algorithme qui construit cette representation intermediaire est fonde sur la transformation de Fourier et s'appelle Super Vocodeur de Phase . Pour nettoyer ou "ameliorer" le sonagramme nous proposons trois techniques supplementaires: l'egalisation, le masquage et l' IrrfFiltrage.
Fig. 1
La technique d'analyse a la base du travail est celle de la transformation de Fourier. Un variante de cette technique adaptee pour l'analyse du son est la transformation de Fourier a court-terme (TFCT). Dans cette transformation une fenetre de ponderation est placee sur le son pour reduire la taille de l'analyse. L'implementation de cette technique a recu le nom de Super Vocodeur de Phase [Depalle 1995, Moorer 1978] (Fig. 1). Nous rappelons l'equation:
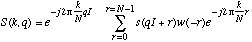
avec
s(n): le n-ieme echantillon du signal
w(n): la fenetre
N: le nombre d'echantillons du signal
I: le pas d'avancement
q: l'indice du temps
k: l'indice des frequences
L'indice k represente la dimension de frequence, l'indice q represente la dimension de temps. S(k, q) est un nombre complexe. Son amplitude est note |S(k, q)|. Fe est la frequence a laquelle le son est echantillonne. Les frequences discretes de l'analyse sont donnees par k.Fe / N. Les temps discretes sont donnes par q.I / Fe.
Les fenetres proposees sont celles de Hanning, Hamming ou de Blackman:
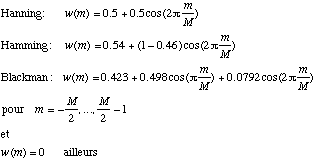
avec M = la longueur de la fenetre. La formule de la TFCT donnee ci-dessus est vraie si M plus petit que N.
Pour l'affichage les spectres S(k, q) sont exprimes en dB. Le spectre equivalent en dB sera note SdB(k, q).
Representation: Le sonagramme est presentee a l'utilisateur sur l'ecran de maniere conventionnelle: horizontal, l'axe du temps; vertical, l'axe des frequence, et en niveau de gris (ou en couleur si on a un ecran couleur!) les amplitudes en dB. Plusieurs exemples sont montres a la fin du texte dans chapitre 6. L'image est munie d'une "scrollbar" sur l'axe du temps et les deux axes peuvent etre etires en temps reel. Ainsi de grands sonagrammes peuvent etre inspectes facilement. L'utilisateur dispose de deux outil de sondage. Le premier permet de selectionner un point precis et de lire les coordonnees exactes de ce point (temps, amplitude, frequence). Le deuxieme permet de selectionner un point precis et d'ecouter le son pur (sinusoide) correspondant aux frequence et amplitude du point. Il a le moyen de regler le contraste en placant deux seuils: les amplitudes inferieures au seuil bas ne sont pas affichees (blanc); les amplitudes superieures au seuil haut sont affichees en noir. Les amplitudes intermediaires sont affichees en niveaux de gris. Ce reglage est en temps reel comme tous les autres outils d'interface. (Ces outils programmes par Chris Rogers etaient deja presents dans AudioSculpt).
On peut travailler a partir de cette representation sub-symbolique et "traitement de signal", mais elle a quelques inconvenients. Des frequences aigues qui sont presentes de maniere pertinentes a l'ecoute ne sont pas necessairement aussi presentes visuellement dans le sonagramme. Par exemple une note aigue d'une flute qui entre sur un fond de frequences basses est clairement presente a l'ecoute malgre sa faible amplitude. Dans le sonagramme par contre elle n'est pas tracee aussi clairement. Cela pose des problemes quand on regle le contraste: les frequences aigues importantes sont masquees, le bruit aux basses frequences reste visible.
Oppose au probleme precedant est le fait que le sonagramme possede beaucoup d'informations non-pertinentes, c'est a dire des frequences presentes dans le signal qu'on entends pas a l'ecoute ou du bruit qu'on ne cherche pas a modeliser.
Pour ameliorer ces problemes nous proposons trois techniques qui nous donnent un sonagramme alternatif et qui doivent nous permettre d'y voir plus clair. Les trois techniques prennent un spectre d'analyse S(K,q) comme entree et le transforment (fig 2). La premiere est une egalisation dans les hautes frequences. Les deux autres proposent une analyse de masquage. La premier s'appelle Masquage, la deuxieme s'appelle IrrFilt.
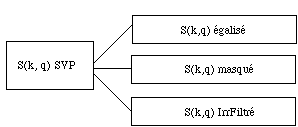
Fig. 2: trois spectres "alternatifs" peuvent etre calcules a partir du spectre Super Vocodeur de Phase
La premiere transformation est une transformation purement "traitement de signal" et nous est donnee intuitivement. Pour ameliorer les hautes frequences nous pouvons appliquer un gain dans les hautes frequences: nous multiplions chaque spectre avec un coefficient egale a 1 pour les basses frequences et plus grand que 1 pour les frequences aigues.
L'idee consiste a diviser le spectre S(k, q) par l'amplitude d'une enveloppe spectrale. Dans ce travail nous avons pris une enveloppe spectrale fixe. Nous avons estime que l'enveloppe spectrale avait une forme en exponentielle decroissante. Nous avons specifie cette courbe par deux parametres: un gain maximal exprime en dB et la pente.
Concretement l'enveloppe estimee se calcule ainsi
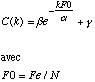
Nous voulons qu'a la frequence Fe/2 l'amplitude de l'enveloppe est minimale et egale a une valeur exprime en decibel. Et nous voulons que l'amplitude de l'enveloppe a zero Hz est maximale et egale a 1. Ces contraintes nous permettent de specifier gamma et beta:
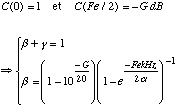
avec G = l'amplitude de l'enveloppe a Fe/2 Hz exprime en decibel. Le spectre S(k, q) est transforme comme suit:
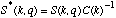
Plusieurs autre methodes peuvent etre imaginees:
* Un filtrage passe-bas de premier ordre pourrait etre utile
* Une meilleure methode pour faire l'egalisation serait de calculer l'enveloppe spectrale avec la technique de la prediction lineaire. Pour une estimation globale de l'enveloppe une prediction avec peu de coefficients suffit. Puis on divise le spectre par cette estimation. Des modules de calcul de l'enveloppe spectrale par la prediction lineaire sont implementes dans AudioSculpt: ce filtrage est imaginable.
* Au lieu d'une courbe fixe, le mieux serait de donner une courbe avant de lancer l'analyse. Si on a une idee du contenu frequentiel, on specifie le gain par une fonction "break point" (BPF, filtrage par segments). Une amelioration serait de pouvoir specifier plusieurs BPF et les temps auxquelles elles doivent etre appliquees. Les BPF sont interpolees entre les temps marques. Cette possibilite sera introduite dans des versions ulterieures de AudioSculpt.
* La meilleure solution serait de pouvoir modifier le contraste localement dans le sonagramme et puis de prendre ces changement en compte dans les analyses suivantes. Cette solution est impossible pour le moment a cause des limitations du systeme.
Pour rendre la representation FFT plus "psycho-acoustique" nous allons soumettre les spectres a un traitement qui est fonde sur les connaissances que nous avons sur le filtrage du son dans la cochlee. Nous proposons deux algorithmes. Les deux sont fondees sur l'effet du masquage .
Le masquage auditif: le systeme auditif ne sait pas toujours separer deux sons presentes simultanement. Le terme utilise pour indiquer ces effets est le masquage. On parle de masquage total si un son (le masque) n'est plus du tout audible s'il est presente simultanement a un autre son (le masquant). On parle de masquage partiel si l'intensite subjective d'un son est reduite lors de sa presentation simultanee a un autre son.
En general le masquage est plus efficace si la frequence du masquant est inferieure a celle du masque. Cette asymetrie est due a la forme de l'excitation (pattern d'excitation) sur la membrane basilaire. Pour un son pur, la region excitee de la membrane basilaire est plus etendue vers le cote qui est sensible aux frequences elevees que vers le cote qui est sensible aux frequences basses. Elle est d'autant plus etendue vers la region des frequences elevees que le niveau du son est fort. La partie de la membrane basilaire excitee par un son de frequence basse avec un niveau fort est alors grande. Le comportement temporel des fibres accordees aux frequences plus elevees est ainsi affecte et le seuil de reponse a leur frequences caracteristique est ainsi augmente. Ainsi l'intensite d'un son de frequence plus elevee qui est presente simultanement peut etre reduit ou le son peut meme ne plus etre percu. Un son de frequence elevee affecte peu le seuil de reponse des fibres accordees aux frequences plus basses, a cause de l'asymetrie dans le pattern d'excitation. [McAdams]
Le premier algorithme que nous utilisons pour le calcul le masquage a ete propose par Terhardt [1982]. Il prend le spectre S(k, q) comme donnees de depart et commence (1) par detecter les pics. Seuls les maxima qui depassent l'amplitude des deux points voisins d'au moins 7 dB sont retenus :
S(i, q) - S(i+j, q) = 7 dB, j = -3, -2 , +2 , +3.
(2) Apres calcul des frequences exactes des maxima par une interpolation et une correction sur leurs amplitudes a cause de la fenetre de ponderation dans la TFCT, les pics sont evalues sur leurs effets de masquage . Deux effets sont pris en compte: l'effet de masquage et le fait qu'un pic peut etre bouge en frequence a cause d'un masquage partiel. Il calcul d'abord le "sound pressure level excess" (SPL) qui decrit la "pertinence auditive" du pic. Le calcul du SPL prend en compte pour une frequence f donne:
* le niveau d'excitation que provoquent les autres pics du spectre a la frequence f,
* le niveau d'intensite des composants qui tombent dans la meme bande critique,
* le seuil d'audition a la frequence f.
Les SPL sont calcules pour tous les pics. Les pics qui ont une pertinence auditive (selon cet algorithme) sont donnes un SPL plus grand que zero. Puis un leger changement de frequence est calcule qui provient d'une interaction de composants tonals presents et simultanes. Le spectre qu'on obtient en prenant les SPL comme amplitude est appele le SPL-pattern.
(3) La degre auquel chaque composant tonal contribue a la perception complete du son depend de son SPL et de sa frequence. Un poids est donnee aux frequences selon leurs position sur l'axe des frequences et prend en compte la dominance spectrale des regions frequentielles. Le vecteur de poids ainsi obtenus est appele le "spectral-pitch pattern" (SP pattern).
(4) Enfin le SP-pattern sert pour le calcul de la hauteur virtuelle. Un candidat hauteur virtuelle est cherche comme sous-harmonique des hauteur spectrales. Le vecteur de poids ainsi obtenus est appele le "virtual-pitch pattern" (VP-pattern)
Nous reprenons quelques remarques de Terhardt sur cette analyse. Il estime que le
SP-pattern represente la base optimale pour la description des phenomenes tonals d'un son.
L'utilisation du SP-pattern ou du VP-pattern depend du probleme a resoudre et du type de son a analyser .
Les composants du SP-pattern ont une valeur entre 0 et 1 et les composants du VP-pattern ont une valeur entre zero et a peu pres trois. Il est alors pas evident d'interpreter ces valeurs en termes d'amplitude dans le sonagramme actuel. Dans le travail propose nous affichons alors seulement le SPL-pattern.
Les resultats du masquage nous sont donnes sous la forme d' une liste de frequences et d'amplitudes ou poids. Avec ces donnees nous reconstruisons un spectre qui sera affiche dans le sonagramme. Nous creons des pics dans le spectre correspondant aux frequences dans la liste. Dans les analyses qui suivent (suite d'accords et suivi de partiel) une detection de pics sera faite qui, elle aussi, fera une interpolation sur plusieurs points autour du maxima. Alors nous devons reconstruire les pics sur plusieurs points pour permettre cette interpolation. Sinon la frequence maximale sera reduite au point discret le plus proche dans le spectre. Pour ceci nous calculons les amplitudes de cinq points autour de la frequence maximale en utilisant la formule d'un parabole:
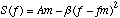
qui passe par l'amplitude maximale Am a la frequence fm. Si on mesure les amplitude a partir de -100dB, la parabole croise l'axe des frequences aux points:
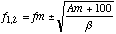
Si on veux qu'au moins 5 points aient une amplitude plus grande que -100 dB il faut que:
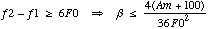
Ainsi des paraboles tres pointe sont crees. Les amplitudes des cinq points autour de fm sont calcules et places dans le spectre de sortie.
Le deuxieme algorithme de masquage auditif, appele IrrFilt (Irrelevance Filter), a ete mis au point par G.Eckel [Deutch 1992]. L'algorithme calcule un "seuil de pertinence" a partir du spectre S(k, q). Les amplitudes en dessous du seuil de pertinence peuvent etre ignorees car il est estime que ces composants spectraux ne sont pas traites par le systeme auditif. Ainsi les spectres sont reduits sans que la qualite du son soit perdue en theorie.
Le seuil de pertinence est calcule a l'aide d'une estimation du pattern d'excitation sur la membrane basilaire. La forme du pattern d'excitation depend de l'intensite mais est considere comme lineaire sur une echelle en Bark, avec une pente de -27 dB/Bark vers les frequences basses et une pente de -24 dB/Bark vers les frequences elevees. Le pattern est donne ainsi:
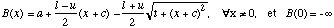
avec:
l = pente aux frequences basses = 27 dB/Bark,
u = pente aux frequence elevees = -24 dB/Bark,
t = coefficient qui arrondit le pic de la fonction = 0.3,
x est mesure en Bark.
Les valeurs des parametres a et c sont donnees en admettant B(0) = 0.
Le pattern B(x) exprime un rapport en dB. B(0) est egal a moins l'infini ce qui veut dire qu'un composant spectral ne peut se masquer lui meme.
Le calcul du seuil de pertinence est construit en convolant le spectre d'amplitudes |S(k, q)| reevalue sur une echelle en Bark, avec le pattern B(x):
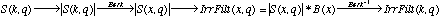
Les spectres S(k, q) sont reduits en gardant ce qui depasse le seuil de pertinence:
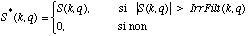
Dialogues: Avant de lancer l'analyse une fenetre de dialogue apparait qui permet a l'utilisateur d'introduire le nombre d'echantillons dans l'analyse, le nombre de points de la fenetre, le pas d'avancement, et le type de fenetre de ponderation (Hanning, Hamming ou Blackman).
La visualisation a ete discutee dans sous le titre du Super Vocodeur de Phase. L'utilisateur a la possibilite de manipuler les resultats affiches dans le sonagramme avant de continuer l'analyse. En reglant le contraste il reduit l'information contenu dans le sonagramme dans les analyses suivantes. En effet, dans les analyses qui suivent, tous ce qui est en dessous du seuil du reglage de contraste (ce qui n'est pas visible sur l'ecran) ne sera pas prise en compte. Ainsi une analyse sur les amplitudes les plus fortes est possible. Cette reduction prealable des donnees rend l'analyse et ses resultats moins lourds. Cette interaction est important car l'utilisateur sait ce qu'il va analyser: ce qui est sur l'ecran. En plus le placement du seuil par l'intermediaire du contraste evite de preciser un seuil fixe.
Maintenant l'utilisateur a le choix entre deux analyses. La premiere permettra d'arriver a une description du son comme suite d'accords. La deuxieme permettra d'arriver a une description du son comme sequence polyphonique.
Introduction: Dans cette representation on estime que le son est une suite d'unites sonores distinctes. Chaque unite sonore commence a la fin de l'unite precedente. D'abord nous cherchons les temps de debut et les temps de fin des unites. Ces dates sont determinees comme les endroits ou le signal change de nature. Entre le debut et la fin nous estimons que l'unite sonore est stable ou que les fluctuations sont petites. Pour chaque unite une representation en forme d'accord est alors donnee. Nous appelons cette maniere de decrire la representation en suite d'accords. (Notons qu'un accord peut etre reduit a une note : dans ce cas on est ramene au suivi de fondamentale).
Plusieurs criteres de decoupage du signal peuvent etre imagines. Nous en avons parle plus haut. On pourrait couper le signal aux endroits ou une nouvelle note commence, aux endroits ou le timbre change, aux endroits ou la tension musicale change et aux combinaisons logiques des criteres precedents. Probablement on veut reperer tous les endroit ou il y a un changement qui est interessant au plan perceptif (par rapport au contexte).
Dans ce travail nous essayons de reperer les endroits ou une nouvelle note ou un nouveau accord commence, un probleme qui s'avere deja assez complique.
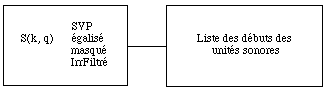
Fig. 3: a partir du sonagramme nous estimons les debuts des unites sonores
Nous allons analyser le sonagramme et essayer de trouver les endroits ou il y a un changement d'energie assez important dans le spectre (fig. 3). Nous allons principalement nous concentrer sur les croissances d'energie presentes dans le spectre. Ainsi nous mettons plus d'attention sur les attaques des notes (naissances des partiels) qu'aux disparitions des notes (morts des partiels).
|S(k, q)|2 est une estimation de l'etalement de l'energie sur les frequences du signal s(n), a l'instant n = q.I . SdB(k, q) exprime cette puissance en dB, et est plus proche des quantifications perceptives. Nous voulons mesurer l'arrive (brusque) ou le deplacement (brusque) d'energie car l'entree d'une note est marquee (pour les sons percussifs en tous cas) par une augmentation d'energie. Egalement, un deplacement rapide de l'energie sur l'axe de frequences designe souvent l'arrive d'une nouvelle note ou est percu comme quel.
Nous calculons ces changements d'energie par la difference des deux spectres:
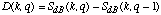
Les differences sont ensuite integrees comme suite:
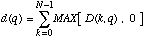
ce que nous appelons la derivee. Nous gardons seulement les differences positives. Ceci nous est donne par le fait que:
* si une nouvelle note entre, nous estimons que l'energie presente dans le spectre S(n) est plus grande que l'energie dans le spectre S(n-1) ce qui resulte en une derivee positive,
* si les deux spectres sont presque identiques comme dans le cas d'un note tenue, les differences sont toutes presque zero et la derive est tres petite,
* s'il y a autant d'energie dans les deux spectres mais qu'elle s'est deplacee sur l'axe des frequences, les differences sont a la fois positives et negatives et la derivee sera positive mais moins prononcee,
* si une note (des partiels) s'arrete les differences seront principalement negatives et la derivee, qui ne prend en compte que les valeurs positives, est tres petite.
Pour diminuer la presence des effets hasardeux et eviter trop de fluctuations dans le calcul de la derivee nous calculons le spectre a l'instant q comme la moyenne des cinq spectres
S(k, q+j), j = 0, ..., 4 et egalement le spectre a l'instant q-1 comme la moyenne des cinq spectres S(k, q-j), j = 1, ..., 5. Le moyennage nous permet de reduire les effets du bruit present dans le signal et de diminuer l'incertitude sur le spectre calcule. En effet un calcul probabiliste montre que la variance de l'estimation du spectre diminue en moyennant [Depalle 1995].
Pour rendre cette derivee independant de l'energie dans le signal a l'instant q, nous la divisons par cette energie, c'est a dire par la somme des amplitudes SdB(k, q), k=0,..., N.
Les changement brusques sont indiques par un maximum de cette fonction. La detection des maxima nous donne des indications sur les endroits ou couper le signal. Cette fonction est (malheureusement) soumise aux fluctuations locales qui donnent lieu a des maxima sans importance. Nous pouvons eviter ce probleme en placant un seuil sur les maxima. Nous voulons eviter de specifier un seuil fixe. Une solution que nous voulons proposer est de donner a l'utilisateur un "slider" avec lequel il peut bouger le seuil. Selon le seuil indique par lui et les amplitudes des maxima nous ajoutons ou enlevons des marqueurs dynamiquement. Quand il estime que le bon nombre de marqueurs est place il appuie sur un bouton et les marqueurs sont fixes. Cette interactivite est prevue dans de futurs developpements. Dans la version actuelle nous placons un seuil exprime en pourcentage de l'ecart entre le maximum maximorum et le minimum maximorum.
Remarque 1: Il est evident que cette methode marche mieux sur des sons de nature percussive. Sur des sons avec des fluctuations lentes dans lesquels les partiels entrent progressivement, cette methode se montrera pas apte a la detection des debuts.
Remarque 2: La derivee est une mesure de distance entre deux spectres consecutifs et l'arrivee d'un evenement est reperee comme un maxima dans cette fonction de distance. Nous voulons remarquer que d'autres mesures de distance sont possible. Citons par exemple la distance mesuree a partir des coefficients de prediction lineaire [Foster 1982; Lepain 1995] et la mesure de distance fondee sur le changement de la frequence fondamentale [Cerveau 1994]
Visualisation et manipulation: Aux endroits ou le son est coupe nous placons un marqueur. Un marqueur se presente comme une ligne verticale sur le sonagramme avec une poignee (handle) a sa base. L'utilisateur a maintenant la possibilite de deplacer les marqueurs, de supprimer des marqueurs ou d'en ajouter. Des exemples sont montres au chapitre 6.
Les temps marques par les marqueurs peuvent etre sortis vers PatchWork. Cette possibilite s'avere interessante et pratique. Souvent un compositeur a besoin de ces donnees pour en extraire un rythme. PatchWork est equipe d'une bibliotheque KANT pour la quantification d'une liste de durees en une notation rythmique. La liste des temps marques est aussi utilisable dans la preparation des donnees des traitements qu'on veut appliquer au son notamment la dilatation dans le temps et la transposition. Les deux transformations sont presentes dans AudioSculpt et acceptent des taux de modification variable dans le temps. Ainsi les marqueurs peuvent aider a decrire cette variation dynamique. Par exemple, dans la quantification dans KANT les durees introduites sont legerement adaptees pour une notation optimale. Ces legeres corrections peuvent etre retransmises vers AudioSculpt comme donnees de dilatation ou de compression pour ajuster le son au rythme note..
Quand l'utilisateur estime que les marqueurs sont bien places il peut continuer l'analyse et extraire une representation du contenu frequentiel dans chaque segment.
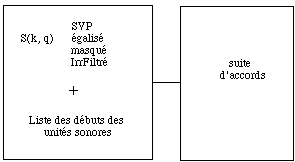
Fig. 4: a partir du sonagramme et la liste des temps de debut des unites sonores nous determinons la suite d'accords
Une fois les marqueurs places l'utilisateur peut demander que lui soit fournie, pour chaque segment, une representation comme accord (fig. 4). Nous estimons que le son entre deux marqueurs est stable et qu'il a un spectre constant. Le segment peut alors etre represente par un seul spectre. Pour ceci nous moyennons les spectres dans le sonagramme entre deux marqueurs:
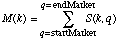
Puis le spectre moyenne est coupe selon le seuil place par le reglage de contraste. Sur le spectre moyenne et coupe nous lancons ou bien
* une detection de pics, ou bien
* une analyse de masquage, (l'analyse de masquage est celle Terhardt dont nous avons parle ci-dessus), ou bien
* une analyse de frequence fondamentale (prevue mais pas encore mis au point en ce moment),
selon la demande de l'utilisateur. Dans les exemples montres dans chapitre 5, nous avons principalement utilise la detection des pics.
L'analyse frequence fondamentale est un algorithme qui a ete concu par Boris Doval [1994].
Visualisation et manipulation: Nous avons par segment une liste de frequences qui represente les frequences de l'accord que nous avons retrouve pour ce segment. Dans le cas de l'analyse frequence fondamentale il s'agit d'une seule frequence. Ces resultats sont visualises sur l'ecran comme des traits horizontaux entre les marqueurs. Les traits sont delimites par deux points ronds. L'utilisateur a maintenant la possibilite de changer les analyses. Il place le curseur sur un des points ronds d'un trait horizontal et il peut deplacer le point en temps et en frequence. Les frequences et les durees des notes peuvent alors etre ajustes. Il peut selectionner le trait en totalite et le supprimer s'il estime qu'il s'agit d'une information inutile. Il peut prendre un point avec le curseur le deplacer et le laisser tomber sur le premier point d'un trait suivant. En faisant ceci les traits sont lies memorises comme un seul trait. Ainsi une note tenue qui a ete coupee par la segmentation peut etre collee et sauvegardee avec sa duree reelle. L'utilisateur a tous moyens de changer et de modifier les resultats comme il veut. Des exemples sont montres en chapitre 6.
Les resultats peuvent finalement etre envoyes vers PatchWork. La communication sera faite en utilisant la technique de "Drag and Drop" et de Apple Events sur Apple Macintosh et est prevue comme prochain developpement. On selectionne tous les traits, on les prend avec la souris, on les deplace et on les laisse tomber dans un editeur de PatchWork. Les donnees sont converties en structures PatchWork et affichees dans un editeur ChordSeq qui prend comme entree une liste d'accords, une liste de durees et une liste d'intensites et les affiches en notation musicale proportionnelle. Maintenant on peut manipuler les donnees comme des structures musicales sur un niveau symbolique, et notamment les quantifier rythmiquement a l'aide de l'editeur KANT en vue d'obtenir une transcription incluant rythmes, hauteurs et intensites.
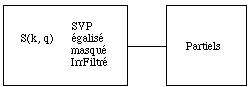
Fig. 5: nous suivons les partiels sur le sonagramme
Introduction: La technique d'analyse dont nous avons parlee ci-dessous decrit le signal comme une suite d'accords. Cette description n'est pas toujours adaptee a tous les sons. Premierement, si le son possede un caractere progressif et non "percussif" la detection des debuts echouera. Dans ce cas on peut toujours decider de placer les marqueurs a la main. Mais, deuxiemement, une description en suite d'accords n'est pas toujours la description optimale ou souhaitee. C'est le cas dans les sons "polyphoniques" ou plusieurs notes (tenues) sont superposees avec des debuts et fins differents. C'est pourquoi nous proposons une deuxieme methode pour analyser le son. Cette methode va essayer de retrouver et de suivre les partiels dans le son. C'est l'analyse qu'on appelle le suivi de partiels (fig. 5). Elle est souvent utilisee par exemple pour determiner les parametres dans une synthese additive. Dans ce cas une analyse fine est necessaire pour retrouver un son realiste a la sortie de la synthese. Bien des algorithmes sont connus qui accomplissent cette tache. Dans le cas ou nous nous mettons nous ne demandons pas une analyse tres detaillee c'est a dire une analyse qui retrouve chaque partiel du son (comme dans le cas de la synthese additive). Nous nous interessons aux partiels les plus pertinents, notamment les partiels qui restent visibles apres le reglage de contraste.
Le suivi de partiels se fait ainsi: chaque spectre du sonagramme est d'abord reduit en coupant tous ce qui est en dessous du seuil du reglage de contraste. Puis nous detectons les maxima. Les frequences des maxima sont calculees plus precisement avec une interpolation polynomiale sur trois points. Nous gardons seulement les frequences et les amplitudes des maxima.
Soient F(n,t), n = 1, ..., N, les frequences des maxima detectes dans le spectre a l'instant t, et F(m,t - 1), m = 1 , ... , M, les frequences des maxima dans le spectre a l'instant t - 1.
Nous definissons une mesure de distance:
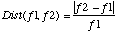
et une distance maximale DMAX (exprimee en intervalle musical par exemple). Ainsi nous ne permettons pas de grands sauts en frequence.
La connexion entre les pics du spectre S(t-1) avec les pics du spectre S(t) est faite comme decrit ci-dessous. A chaque fois nous partons du spectre qui a le moins de pics (S(t) ou S(t-1)). Les connections sont faites en evitant que deux partiels se rejoignent ou au contraire qu'un partiel se divise en deux. Les pics ne peuvent alors etre attribues qu'a un seul partiel. C'est dans ce controle que les deux sous-algorithmes different :
Si M plus grand que N,
dans ce cas il y plus d' "anciens" pics que de "nouveaux" pics. Les connections sont cherchees a partir de S(t).
* Pour chaque pic F(n, t), n = 1, ... , N, de S(t) nous cherchons le pic F(j, t-1) de S(t-1), j entre 1 et M, pour lequel Dist(F(n,t), F(j, t-1)) est minimale.
* Si la distance minimale est plus que petite que DMAX, on regarde si le pic F(j, t-1) n'a pas encore ete connecte avec un pic F(i,t), i!=n. Ainsi nous evitons qu'un partiel se divise en deux. Si en effet le pic trouve F(j, t-1) a deja ete connecte avec un pic F(i,t), i!=n, on connecte F(j, t-1) avec le pic (F(i,t) ou F(n,t)) pour lequel la distance est la plus petite.
* Si la distance minimale est plus grande que DMAX la connexion entre F(n,t) et F(j, t-1) n'est pas etablie.
* Les frequences F(n,t) qui ne sont pas connectees commencent des nouveaux partiels. Les frequences F(m,t-1) qui ne sont pas connectees terminent des partiels.
Si M plus petit que N,
dans ce cas il y moins de d' "anciens" pics que "nouveau" pics. Dans ce cas nous partons de S(t - 1).
* Pour chaque frequence F(m,t - 1) nous cherchons le pic F(i, t) de S(t), i entre 1 et N, pour lequel Dist(F(m,t-1), F(i, t)) est minimale.
* Si la distance minimale est plus que petite que DMAX, on regarde de nouveau si le pic a distance minimale F(i, t) n'a pas encore ete connecte avec un pic F(j,t-1), j!=m. Nous voulons eviter que deux partiels paralleles ce rejoignent et continuent comme un seul. Si en effet F(i,t) a deja ete connecte avec F(j, t-1), j!=m, on fait la connexion entre F(j, t-1) ou F(m, t-1) avec F(i, t) selon la distance la plus petite.
* Si la distance minimale est plus grande que DMAX la connexion entre F(m,t-1) et F(i, t) n'est pas etablie.
* Les frequences F(n,t) qui ne sont pas connectees commencent des nouveaux partiels. Les frequences F(m,t-1) qui ne sont pas connectees terminent des partiels.
Les partiels sont memorises en gardant le temps de debut et la liste des frequences et des amplitudes des pics. Nous gardons seulement les partiels qui ont une duree plus longue que 100 msec. Comme nous l'avons deja dit nous sommes interesses aux partiels les plus significatifs. Ces partiels sont principalement de longue duree; les partiels plus petit que 100 msec par contre suivent souvent des pics hasardeux ou du bruit.
Cette methode simple nous donne des resultats satisfaisants.
La mesure de distance que nous avons prise est une mesure qui est relative a la frequence. La plage des frequences acceptees est d'autant plus grande que la frequence est elevee. Dans l'implementation actuelle DMAX est egale a 0.06 ce qui correspond a un intervalle musical d'un ton. Avec cet intervalle il est possible de suivre les vibratos. Un vibrato d'une amplitude d'un demi ton et d'une frequence de 8 Hz a une pente de 8[[pi]], exprime en tons par seconde. Le saut en frequence maximal entre deux echantillons du vibrato est alors 8[[pi]]/Fe tons ce qui est plus petit qu'un ton.
Un intervalle trop grand permet des sauts en frequences trop grandes et permet qu'un partiel saute a une frequence trop eloignee et continue de maniere erronee. Un intervalle trop petit couperait les partiels dans le cas d'une variation de frequence accidentelle.
D'autres mesures peuvent etre donnees comme par exemple la distance euclidienne. La mesure de distance peut dependre des amplitudes. La mesure que nous avons prise est adaptee a l'echelle musicale qui s'exprime egalement de maniere relative et s'est montree jusqu'a maintenant bien adaptee.
Visualisation et manipulation: Les partiels trouves sont affiches sur l'ecran comme une suite de points ronds lies entre eux. De nouveau l'utilisateur peut placer le curseur sur un des points ronds et le deplacer en temps et frequence. Un point egare ou mal place est alors corrige. L'utilisateur peut selectionner le partiel en totalite et le supprimer (la suppression d'un partiel en total n'est pas encore developpe au moment ou nous ecrivons). Il peut prendre un point avec le curseur, le deplacer et le laisser tomber sur un point d'un partiel suivant. En faisant ceci les deux partiels sont lies est memorises comme un seul objet. Si un partiel a ete coupe en deux (parce qu'une modulation d'amplitude l'a fait disparaitre de l'ecran) les deux parties sont rattachees. Il peut selectionner un seul point et le supprimer. S'il s'agit d'un point au milieu d'un partiel, le partiel est divise en deux et les deux parties sont memorises separement. Un partiel qui bascule de maniere erronee et continue par un partiel a une frequence differente peut etre separe en deux partiels. Des exemples sont montres en chapitre 6.
Comme pour la representation en suite d'accord les resultats peuvent etre envoyes vers PatchWork. La communication sera egalement faite par "Drag and Drop" et Apple Events. On selectionne un ou tous les partiels, on les prend avec la souris, on les deplace et on les laisse tomber dans un patch de PatchWork (prevue). Les donnees sont converties en structures PatchWork (hauteur, debuts, duree et amplitude) et affiches dans un editeur ChordSeq. Maintenant on peut manipuler les donnees comme structure musicale a un niveau symbolique.
Une fois qu'un partiel a ete correctement trace et memorise un ensemble d'information peut etre calcule.
* Nous pouvons calculer la frequence et l'amplitude moyenne du partiel. Ce sont ces donnees qui pour le moment sont transmises a PatchWork. On peut egalement imaginer de tracer un polynome de premier ou de deuxieme ordre ou une fonction exponentielle a travers les points. Les coefficient de ces fonctions peuvent nous indiquer s'il s'agit d'un partiel stable ou s'il s'agit d'un glissando.
* Nous pouvons exporter la frequence au debut du partiel et la frequence a la fin du partiel. Ces donnees peuvent etre souhaitees pour decrire un glissando.
* Si le partiel est soumis a un vibrato nous pouvons essayer de decrire ce vibrato. Nous faisons reference au travail de Jerome Daniel [1995]. Egalement, si le partiel possede une modulation en amplitude nous pouvons la caracteriser et egalement la transmettre a PatchWork.
* Nous pouvons estimer s'il s'agit d'un son percussif ou plutot d'un son entretenu en inspectant l'evolution des amplitudes dans le temps. (temps d'attaque)
* Nous pouvons examiner le total des partiels et les regrouper selon des criteres donnees. Une premiere idee est de les regrouper selon le temps de naissance ou le temps de disparition. Un autre critere de regroupement est la relation harmonique. Nous faisons reference au travail de Brown qui fait une analyse spectrale, un "suivi de partiels" suivi d'un regroupement sur temps de naissance et relation harmonique [Brown G.J 1992]. Il travail avec une modele psycho-acoustique (modele d'oreille) mais les idees sont exploitables. Avec ce regroupement il espere retrouver les notes. Il a continue ce travail sur un plan superieur et regroupe les notes detectees sur des criteres de brillance et d'asynchronie dans la naissance des harmoniques [Brown and Cooke]. Ce delai est tres probablement une dimension dans la description du timbre. Ce regroupement permet alors de separer dans un enregistrement de deux instruments les deux voix et de les transcrire separement.
* Nous pouvons essayer de retrouver la methode de resynthese optimale. Par exemple un son pur avec modulation de frequence est decrit de maniere beaucoup plus simple par la frequence moyenne, taux de modulation et frequence de modulation que par la description synthese additive.
* Une possibilite qu'on peut prevoir c'est de resynthetiser un seul partiel ou un ensemble de partiels selectionnes. Les applications sont multiples. Par exemple, un compositeur veut synthetiser un son qui est intimement lie avec un son enregistre mais en meme temps de nature differente. Il analyse le son enregistre et en retient une groupe de partiels qui le caracterise. Il resynthese ces partiels qu'il manipule ensuite pour arriver a un son plus riche. Les deux sons sont alors different mais ont un caractere commun qui est fortement lie a la specificite du son de depart.
* Un dernier point qui suit la remarque du point precedent. Une fonctionnalite tres interessant serait de selectionner un seul ou un ensemble de partiels, de les transposer en frequence et en temps et de resynthetiser le son avec les partiels "transplantes".
Nous faisons un resume des analyses proposees.
A partir du son nous construisons une representation amplitude-frequence-temps: le sonagramme.
Quatre variantes sont possible: le sonagramme SuperVP, le sonagramme Masquage, le sonagramme IrrFilt et le sonagramme Egalise. A partir de cette representation nous avons la detection des evenements, et suivi de partiels. A partir du sonagramme complete par la liste des evenements nous avons la detection de la suite d'accords. Les partiels et la suite des accords sont transmis vers PatchWork dans un editeur ChordSeq. Cet editeur est plus adapte pour des sequence d'accord (voila son nom) mais avec un astuce on peut afficher des formes polyphonique. Dans PatchWork un module KANT peut extraire le rythme et les deux (rythme et notes/accords -- incluant les intensites de leurs composantes) sont affiches dans l'editeur RTM.
Schematise cela donne: (page suivante)
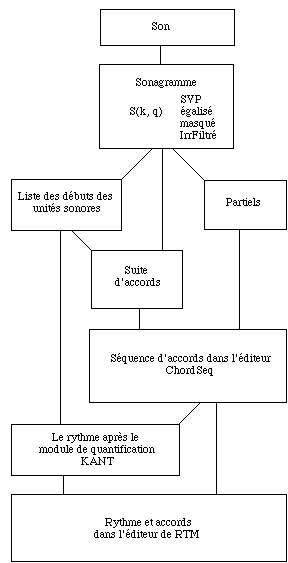
Fig. 6: le schema complet des representations qu'on peut extraire a partir du son
Je voudrais dire quelques mots sur l'aspect programmation et l'architecture de AudioSculpt.
AudioSculpt est une couche graphique construite au dessus de Super Vocoder de Phase, ecrit en C. Super Vocodeur de Phase est responsable des analyses et des traitements des sons. Super Vocodeur de Phase lui meme depend largement de la bibliotheque UDI, qui est une bibliotheque vectorielle de traitement. Dans SuperVP on cree des patches. Un patch est un ensemble de modules de traitement de signal. Les modules sont places l'un apres l'autre et chacun s'occupe d'une partie de l'analyse. Le premier lit le son, le deuxieme fait l'analyse (de FFT par exemple), le troisieme constitue le filtrage. Apres le module de filtrage on peut ajouter des modules de resynthese et de sortie.
Dans le projet un module de filtrage a ete ajoute. Ce module prend un spectre S(k, q) et le transforme en spectre "equalise", "masque", "IrrFiltre" ou "coupe" comme decrit en haut. De plus il transmet les amplitude du spectre en Decibels pour l'affichage dans le sonagramme. Les patches que nous construisons dans le projet sont composes d'un module d'entree de son, d'un module analyse FFT puis du nouveau module de filtrage.
Les quatre transformations sont independantes l'une de l'autre a l'interieur du nouveau module. Elles sont activees en mettant des "flags" a la construction du module. L'ordre des transformation a l'interieur du module est ensuite: egalisation, IrrFilt, masquage, couper, conversion en dB. Un exemple: on applique le IrrFilt, puis on coupe le spectre ensuite on convertit les amplitudes en dB. Beaucoup de combinaisons sont possibles, mais peu ont vraiment du sens.
Dans AudioSculpt (ecrit en C++) nous avons ajoute deux classes CPeach et CVisualPartial. La premiere CPeach (Peach est un nom de projet) qui sert simplement pour encapsuler les modifications qui sont introduites dans AudioSculpt. Elle n'herite d'aucune classe et elle n'est pas sous-classee. Tous les commandes qui sont lances a partir des menus sont envoyes vers cette classe qui assure toutes les actions necessaires. Elle ne communique qu'avec deux autres classes: la classe CFilterPane et CSpectrumPane. CFilterPane est la classe qui s'occupe de la fenetre de presentation du sonagramme et des objets d'interface qui lui sont rattaches : les marqueurs, les polygones pour le filtrage, les breakpoint functions. Dans cette classe nous avons ajoute un variable pour l'affichage des partiels. CSpectrumPane est la classe qui s'occupe specifiquement du calcul et de l'affichage du sonagramme a l'interieur de la fenetre. Dans cette classe nous avons ajoute des methodes pour l'affichage des sonagrammes alternatifs.
La deuxieme classe implementee, CVisualPartial, herite de la classe EmbeddedBreakPt qui elle meme herite de BreakPtList. EmbeddedBreakPt sert pour l'affichage des analyses de frequence fondamentale et de masquage (Terhardt) qui etaient deja presents dans AudioSculpt. Nous avons sous-classe EmbeddedBreakPt pour la visualisation des partiels sur l'ecran et ajoute les structures pour sauvegarder les amplitudes. Pendant l'analyse meme des structures dynamiques sont creees car on ne connait pas le nombre de partiels ni le nombre de points dans chaque partiel. Apres l'analyse les structures dynamiques sont copiees dans des instances de CVisualPartial et affichees sur l'ecran. Les resultats de l'analyse de suite d'accords sont egalement copies dans des instances de CVisualPartial. Les deux methodes importantes que nous avons ajoutees sont DragAndConnect et DeletePoint. DragAndConnect connecte deux partiels sous le controle de l'utilisateur. DeletePoint enleve un point d'un partiel et cree un nouveau partiel si necessaire.
Nous avons egalement ajoute un menu dans Audiosculpt sous le nom de Peach (sans explication de ce nom). Dans ce menu huit fonctions sont offertes:

Fig. 7: menu ajoute dans AudioSculpt
* Sonagram after Masking: affichage du sonagramme masque,
* Relevant Sonagram: affichage du sonagramme IrrFiltre,
* Equalized Sonagram: affichage du sonagramme egalise,
* Partial Tracking: lance le suivi de partiels,
* Place Marker: lance l'analyse de detection des debuts,
* Add Marker: ajoute un marqueur sur l'ecran,
* Chord Sequence: lance l'analyse de suite d'accords,
* Export Markers: sauvegarde les temps marques dans un fichier,
* Export Partials: sauvegarde le temps de naissance, la duree, la frequence moyenne et l'amplitude moyenne des partiels (les resultats de l'analyse suite d'accords sont egalement sauvegardes comme des partiels) dans un fichier. Les partiels sont d'abord tries sur leurs temps de naissances.
* Clip and Synthesis: resynthese du son apres seuillage. (voir titre suivant).
L'ajout des modules dans l'environnement existant a cree quelques outils utilisables. Notamment l'existence des modules de resynthese nous permet de resynthetiser le son a partir des spectres transformes.
Ainsi il est possible:
* d'egaliser le son dans les hautes frequences,
* de reduire le contenu frequentiel en utilisant le reglage de contraste,
* de reduire le contenu frequentiel utilisant le IrrFilt
* de combiner le clipping avec IrrFilt ou l'egalisation.
La resynthese a partir du sonagramme reduit par le contraste s'avere un outil tres interessant. Ainsi nous avons pu couper de legers bruits de fond, des bruits faibles etales sur toute la plage des frequences.
Pour la resynthese des spectres masques devrons encore ajouter une fonction pour convertir les resultats en dB en amplitudes "reelles".