Spatialisation sur écouteurs pour les applications de réalité virtuelle
Une étude d'envergure a été consacrée aux techniques de reproduction sur écouteurs qui font appel à la synthèse binaurale. Ce principe de spatialisation permet de suggérer la présence d'une source selon toute incidence et constitue à ce titre un facteur important d'immersion pour les systèmes de réalité virtuelle. Le travail a été réalisé principalement au cours de la thèse de V. Larcher [Larcher 01]. Les points d'étude majeurs ont été le développement de formats d'encodage binaural multicanal et les procédés d'adaptation individuelle. Ces éléments apportent une réponse aux principaux freins qui empêchaient jusqu'alors le déploiement à grande échelle de cette technologie, en particulier :
le coût de calcul, important au regard des autres techniques de spatialisation.
Format binaural multicanal [Larcher00] [Rio 02].
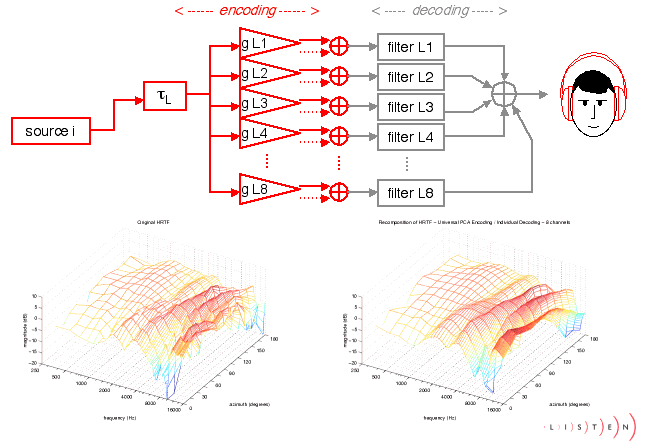
Une réduction du
coût dimplantation de la synthèse binaurale peut être
obtenue par une décomposition linéaire des HRTF (Head Related
Transfer Function) sur une base de fonctions spatiales ou sur une base
de filtres. Sur le plan algorithmique, cette décomposition est associée
à une implantation qui repose sur un format d'encodage intermédiaire
multi-canal couplé à un décodeur binaural formé
par ce jeu de filtres de base. A l'étape d'encodage, chaque source
n'engage qu'un coût de calcul limité correspondant à
un ensemble de gains gérant la distribution des sources sur les
différents canaux en fonction de la direction désirée.
L'avantage est que le coût de calcul principal constitué par
les filtres de reconstruction est consigné dans l'étage de
décodage; il est par conséquent indépendant de la
complexité de la scène sonore. Cette technique permet également
un arbitrage en termes de nombres de canaux d'encodage (scalabilité).
On pourra par exemple choisir la précision d'encodage en fonction
de l'importance accordée à la localisation des sources sonores
(source de premier ou de second plan, son direct ou sources-image liées
à la restitution de l'effet de salle).
Plusieurs décompositions ont été comparées, différant sur le type de contrainte imposée. Dans le premier cas, on fixe la base de fonctions spatiales comme étant les harmoniques sphériques. Le format dencodage issu de cette décomposition est désigné par Binaural B. La seconde méthode fixe la base de filtres comme étant un sous-ensemble de HRTF, lobjectif étant de pouvoir engendrer toutes les HRTF à partir de la mesure de peu dentre elles. Enfin, la troisième méthode réalise la décomposition sans contrainte ni sur les fonctions spatiales ni sur les filtres, et obtient les composantes minimisant lerreur de reconstruction par une méthode danalyse statistique (Analyse en Composantes Principales). Ces méthodes ont été comparées au regard de différents critères : la précision de reconstruction des HRTF, lefficacité en coût de calcul de lencodeur (support disjoint des fonctions spatiales), le caractère universel de lencodeur (indépendance du format intermédiaire par rapport au sujet).
Adaptation individuelle de la synthèse binaurale [Larcher 01]
Les HRTF, filtres à
la base de la synthèse binaurale, varient en fonction de l'incidence,
mais également en fonction de la tête sur laquelle ils ont
été mesurés. A l'origine de ce phénomène
: la morphologie de la tête, qui, faisant obstacle au son incident,
modèle les caractéristiques temporelles et fréquentielles
des HRTF. Une écoute binaurale non individuelle, i. e. proposant
à l'auditeur des HRTF différentes des siennes, entraîne
une augmentation des artefacts de localisation (ambiguité avant-arrière).
Plusieurs stratégies permettant d'atténuer les effets d'une
écoute non-individuelle ont été étudiées.
Un premier effort d'adaptation
individuelle peut être réalisé à l'aide d'une
adaptation
discrète, appairant un auditeur avec l'une des têtes constituant
la base de données. Cette approche repose sur une méthode
d'évaluation de la distance entre la tête de l'auditeur et
les têtes de la base à partir d'un ensemble de relevés
morphologiques (largeur du cou, largeur de la tête, profondeur de
la tête, longueur du pavillon, longueur de la conque, largeur de
la conque,
). Ce critère permet ensuite de piloter le choix du
jeu de HRTFs le plus adapté à l'individu.
Une autre approche, dénommée
adaptation
continue, consiste à synthétiser les HRTF de l'auditeur
final en s'appuyant sur les corrélations entre les paramètres
morphologiques et les caractéristiques spectrales des HRTF. Une
tête est alors "transformée" en une autre par morphisme des
caractéristiques spectrales des HRTF et des indices de retard interaural.
L'ensemble de ce travail est arrivé aujourd'hui à maturité et fait l'objet de travaux d'optimisation et d'intégration dans le cadre du projet LISTEN ( cf. Section Projets de valorisation dédié à la réalité augmentée dans un contexte muséologique. Des messages, commentaires didactiques, extraits musicaux ou effets sonores sont intégrés dynamiquement dans une scène sonore individualisée en fonction des déplacements du visiteur et restituée en 3D, sur écouteurs, grâce à la technologie binaurale. Les deux points cités plus haut, complexité des scènes sonores et adaptation individuelle trouvent un terrain d'application privilégié au travers de ce projet.