We have applied our method to two acoustic time series, a single
saxophone tone, consisting of 16000 samples sampled at 32kHz and a speech
signal of the word manna![]() . The latter time series consists of 23000 samples with a
sampling rate of 44.1kHz. Both time series have been normalized to
stay within the interval
. The latter time series consists of 23000 samples with a
sampling rate of 44.1kHz. Both time series have been normalized to
stay within the interval 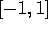 . The estimation of the dimension
of the underlying attractors yields a dimension of about 2-3 in both
cases.
. The estimation of the dimension
of the underlying attractors yields a dimension of about 2-3 in both
cases.
We chose the control input 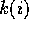 to be linear increasing from
to be linear increasing from 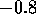 to
to 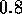 . Stable models we found for both time series using
. Stable models we found for both time series using 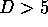 . Namely for the parameter TT we observed considerable impact on
the model quality. While smaller TT results in better one step
ahead prediction, the iterated model often becomes unstable. This
might be explained by the decrease in variation within the prediction
hyperplane, that has to be learned. For small TT the model tends to
become linear and does not capture the nonlinear characteristics of
the system. Therefore the iteration of those models failed.
. Namely for the parameter TT we observed considerable impact on
the model quality. While smaller TT results in better one step
ahead prediction, the iterated model often becomes unstable. This
might be explained by the decrease in variation within the prediction
hyperplane, that has to be learned. For small TT the model tends to
become linear and does not capture the nonlinear characteristics of
the system. Therefore the iteration of those models failed.
To large values of TT results in an insufficient one step ahead
prediction error, which pushes the model far away from the attractor
also producing unstable behavior.