This section will give a brief introduction to, and a formal definition of, the basic concepts and methods of the theory of digital signal processing used in this project. They form the basis for the methods presented in the subsequent chapters. Necessarily, this introduction will be very brief and restricted. In particular, I will consider the theory of digital signal processing apart from the more general theory of analog signal processing, and will pass over the various problems and mathematical prerequisites one has to take care of (stability, convergence). See [RH91] for a broad introduction, [Rob98] for an online tutorial, and [OS75] for a more profound presentation.
The audio data we wish to treat will generally be present in the form of electric oscillations. These can either come from a microphone recording acoustic sound waves, from a tape, or an electronic instrument or device. To convert these oscillations to a form that can be treated by a computer they have to be digitised, i.e. reduced from an analog form (time- and value-continuous) to digital (time- and value-discrete). This process is called A/D conversion or sampling . It consists of two steps:
The index n of the sampled signal x(n) is related to time by t = nts such that
The result of A/D conversion is shown in figure 2.3. It is a curve with discrete steps at every sample. Note, however, that for most of the theory of digital signal processing, as for the rest of this chapter, the samples are generally considered to be value-continuous.
There are various sources of errors in the process of A/D conversion, including jitter, quantization noise, and aliasing:
Converting a digital signal back to an analog signal is called D/A conversion . Roughly, it consists of reading the samples and generating an electric oscillation accordingly. As this will look like the step-curve in figure 2.3, it has to be smoothed by a low-pass filter (a filter that lets only the frequencies below his cutoff-frequency pass) to yield a signal suitable to being amplified and played via loudspeakers, or recorded on analog tape.
The notion of energy and power for digital signals is only slightly related to the physical units pertaining to analog electrical signals. They are, nevertheless, related to the perceived loudness, albeit in a non-trivial way.3.2
The power of a signal x(n) is defined by
Taken as such, this value doesn't tell us much. It is useful,
however, to compare two signals. For this end, the unit decibel
(dB) is introduced: The ratio R in dB of two signals with energies E1and E2 is
After A/D conversion, the signal x(n) is represented in the time
domain as a sequence of numbers. According to Fourier's ingenious
idea , any function, even nonperiodic ones,
can be expressed as a sum of (periodic) sinusoids (which can not be
further decomposed, i.e. they are ``pure''
3.3
). In the complex domain, a sinusoid can be expressed by
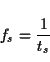


So, to reveal the frequency structure of x, it can be converted
to a frequency domain representation X by the discrete Fourier
transform (DFT):
The result of the Fourier transform in (2.9) is N complex
numbers X(k) which define the magnitude spectrum M(k) and
phase spectrum ![]() for a discrete frequency k:
for a discrete frequency k:
The magnitude spectrum gives the intensity of a sinusoid at frequency k, while the phase spectrum gives its shift in time. Often, the phase spectrum is ignored (it is not important for speech recognition), and the term Fourier spectrum or spectrum is used for the magnitude spectrum.
There exists a generalization of the discrete Fourier transform
3.4,
called the Z-transform , which often simplifies the
representations in the frequency domain. The Z-transform X(z) of a
discrete sequence x(n), where z is a complex variable, is defined
as:
If z is substituted by
 ,
the relationship to the
Fourier transform is obvious. See [OS75] for a rigorous
presentation of the Z-transform, or [Mel97] for an on-line tutorial.
,
the relationship to the
Fourier transform is obvious. See [OS75] for a rigorous
presentation of the Z-transform, or [Mel97] for an on-line tutorial.
The computational complexity of the DFT, when computed directly, is
O(N2). By taking advantage of the periodicity of the analysing
sinusoid
 and applying the divide and
conquer principle of splitting the problem into successively smaller
subproblems, a variety of more efficient algorithms of complexity
and applying the divide and
conquer principle of splitting the problem into successively smaller
subproblems, a variety of more efficient algorithms of complexity
![]() have been developed which came to be known collectively as
the fast Fourier transform (FFT). They generally require that Nbe a power of two. As the discrete Fourier transform and its inverse
differ only in the sign of the exponent and a scaling factor, the same
principles lead to the inverse fast Fourier transform (IFFT).
have been developed which came to be known collectively as
the fast Fourier transform (FFT). They generally require that Nbe a power of two. As the discrete Fourier transform and its inverse
differ only in the sign of the exponent and a scaling factor, the same
principles lead to the inverse fast Fourier transform (IFFT).
The fundamental operation of digital signal processing is the
convolution of two signals x(n) and h(n) to yield y(n), defined by
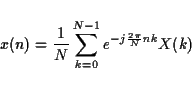
This is what is behind the notion of filtering : The output
signal y is x filtered by h. It is usually expressed
graphically as shown in figure 2.4. This operation is
commutative and associative:
| x(n) * h(n) = h(n) * x(n) | (3.3) | ||
| h1(n) * (h2(n) * x(n)) = h2(n) * (h1(n) * x(n)) = (h1(n) * h2(n)) * x(n) | (3.4) |
Systems which perform linear operations such as convolution, addition, and multiplication by a constant are part of the class of linear time-invariant systems (LTI systems ). 3.5 They are notated as in figure 2.5.
The properties of linearity and time-invariance are defined as:
| T [ a x1(n) + b x2(n) ] | = | a T [x1(n)] + b T [x2(n)] | (3.5) |
| y(n) = T [x(n)] | (3.6) |
As a consequence, an LTI system is completely defined by its
impulse response h(n), which is the output of the system to a
single unit impulse ![]() with
with
An important property is that a convolution of two signals in the
time-domain can be expressed by a multiplication of their spectra in
the frequency-domain. If X, Y and H are the Z-transforms of
x, y and h, then
The above provides the link between the intuitive notion of filtering as a selective attenuation or amplification of certain frequencies in a signal to the mathematical operations of convolution and Fourier transformation.
So far, we have considered the signal as a whole, even if it was of
infinite length. For practical applications, and in order not to lose
all time information in the transition to frequency domain, small
sections of the signal of about 10-40 ms are treated one at a time.
These small sections are called windows or
frames . To avoid introducing artefacts into
the frequency-domain, caused by discontinuities at the borders of the
window, the signal is first multiplied by a window function
w(n), which provides for a smooth fade-in and fade-out of the
window.
In the following, the formulas and graphs of some of the most widely used window functions are shown, together with the magnitude spectra of a signal consisting of two sinusoids at different frequencies and amplitudes, multiplied by the corresponding window function. These spectra show the distortion or smear that is introduced by the window function. Ideally, there would be only two sharp peaks.
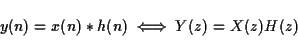
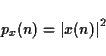
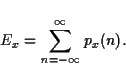
![$\displaystyle \angle X(k)
= \arctan \left\vert \frac{\makebox[3.5ex]{\textbf{re\hfill}} X(k)}{\makebox[3.5ex]{\textbf{im\hfill}} X(k)}
\right\vert$](img29.gif)
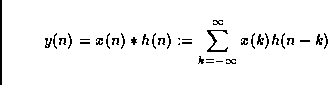
![\begin{figure}% latex2html id marker 1941
\centerline{\epsfbox{pics/Bartlett.eps...
...lett window function]
{The Bartlett window function and its effect}\end{figure}](img49.gif)