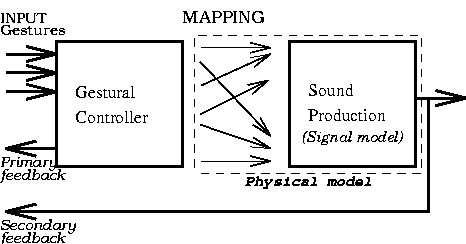
figure 1: Composed (virtual) instrument model.
figure 1: Composed (virtual) instrument model.
By gestural controller we mean the part of the CMI where physical interaction with the player takes place. Conversely, by sound generation unit we mean the synthesis algorithm and its controls. The mapping layer refers to the liaison strategies between the outputs of the gestural controller and the input controls of the synthesis algorithm.
This separation is impossible in the case of traditional acoustic instruments, where the gestural interface is also part of the sound production unit. If we take, for instance, a clarinet, the reed, keys, holes, etc. are at the same time both the gestural interface (where the performer interacts with the instrument) and the elements responsible for the sound production. The idea of a CMI is analogous to "splitting" the clarinet in a way where one could separate these two functions (gestural interface and sound generator) and use them independently.
Furthermore, in a CMI, the notion of a ``fixed'' causality does not always apply. The same gesture (cause) can lead to completely different sounds (effects). As an example, Axel Mulder [1] considers a CMI (or VMI - Virtual Musical Instrument, as he has called it) as capable of capturing any gesture from the universe of all possible human movements and use them to produce any audible sound.
Clearly, this separation of the CMI into two independent units is potentially capable of extrapolating the functionalities of a conventional musical instrument, the latter tied to physical constraints. Nevertheless, how can one keep some of the conventional instruments' features usually needed to allow fine control of the instrument, such as force feedback? How to design gestural interfaces capable of permitting some kind of virtuosistic performance?
Let's move to the next section where we analyse a generic gestural interface, and review some classification of gestures proposed in the literature.