|
|
| 1.3 Multi-tasking |
|
|
|
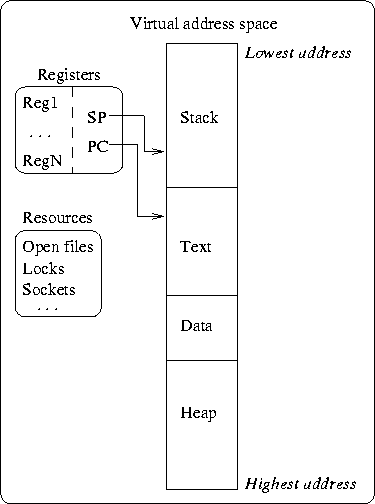
Uniprocessor computers can only accomplish one task at a time. To simulate concurrency, multitasking techniques are used. Time-sharing systems allowing the users simultaneous access have been around for a long time. The standard Unix term for an active task in an operating system is a process. A process can be thought of as a computer program in action. Associated with a process are a number of system resources, such as a memory address space, files, and other system resources. The process also includes a program counter, a stack pointer, a set of registers. Many process can be running concurrently, each process in its own protected virtual address space. Limited communication between process is possible thru secure kernel mechanism (signals, sockets, shared memory). This separation of processes must guarantee that one process cannot corrupt another process (Fig. 1.4). The operating system is able to emulate multiple simultaneous tasks by giving each process a chance to run on the CPU for a limited amount of time. Intelligent scheduling of the processes can give the user the impression of truly simultaneous activities. There are many occasions when a process does not require the CPU, for example, when the program is waiting for user input. While the process waits for input/output, the system gives the CPU to other deserving processes. The suspending of one process and the resuming of another is called a process context switch. The system saves the registers, the program counter, the stack pointer of the suspended process and re-installs those of another, runnable process. What process is scheduled next is determined by the scheduling algorithm.
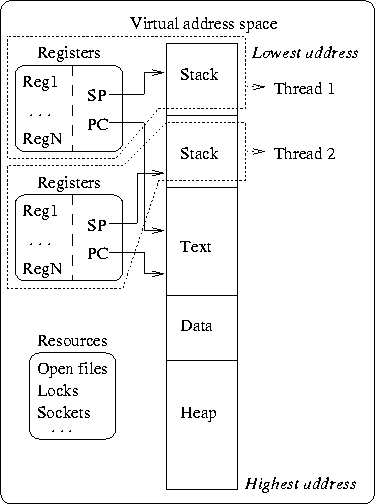
A process executes one program. Processes run in their own address space and have their own resources. Communication between processes is limited, mainly to prevent one process from corrupting another. In many cases concurrency within a given program can be desirable. The old way of designing multiple tasks within a process was to fork of a child process to perform a subtask. In the the eighties, the general operating system community embarked upon several research efforts focused on threaded program designs, as typified by the Mach OS developers at Carnegie-Mellon [Loe92]. With the dawn of the nineties, threads became established in various UNIX operating systems. The thread model takes a process and divides it into two parts. The first part contains resources used across the whole program, such as program instructions, global data, the virtual memory space, and file descriptors. This part is still referred to as the process. The second part contains information related to the execution state, such as program counter and a stack. This part is referred to as a thread [NBPF96]. A process can integrate several threads (Fig. 1.5). Threads are the units of execution; they act as points of control within a process. The process provides the contained threads with an address space and other resources.
Not all operating systems provide threads. For those systems that do not provide threads it is possible to use a thread library. Languages implementations that define threads as a language constructs generally do not rely on threads provided by the operating system but provide their own thread system. The overwhelming reason to use threads over multi-processes lies in the following benefit: threads require less program and system overhead to run than processes do. This translates into a performance gain. We give a concrete example taken from the Real-Time Encyclopedia: on the IRIX systems developed by Silicon Graphics Inc. a process context switch takes 50 micro-sec, while a thread context switch takes 6 micro-sec. Another advantage is that all threads share the resources of the process in which they exist. Multiple processes can use shared memory if specially set up. However, communication between processes involves a call to the system and is more expensive than communication between threads. Communication between threads can usually be done in the user address space. The operating system continuously selects a single thread to run from a systemwide collection of all threads that are not waiting for the completion of some I/O or are blocked by some other activity. It is beneficial to give those threads that perform important task advantage over those that do background work. The choice of any given thread for special scheduling treatment is determined by the setting of the thread's scheduling priority, scheduling policy, and scheduling scope. When the system needs to determine what thread will run, it should find out which thread needs it most. The threads priority determines which thread, in relation to the other threads, get preferential access to the CPU. In general, the system holds an array of priority cues. When looking for a runnable thread the system starts looking in the highest priority queue and works its way down to the lower priority queues to find the first thread. When and how long the thread runs is determined by the scheduling policy. Well known scheduling policies are first-in-first-out (FIFO), round robin, and time sharing with priority adjustments. FIFO picks the first thread out of the queue and lets it run till it blocks on a I/O operation. The blocked thread is then inserted at the end of the queue. The round robin policy lets the thread run for fixed amount of time, called a quantum. If the thread does not block before the quantum, the scheduler blocks the thread and places it at the end of the queue. The time sharing with priority adjustments will increase the threads priority if it blocks before the quantum expires. Threads blocking on I/O are given privileges over CPU consuming threads using all their quantum. Furthermore, threads can be scheduled within system scope or within process scope. When scheduling occurs within system scope, the thread competes against all runnable processes and threads on the system level. The system scheduler determines which threat or process will run. When scheduling occurs in process scope, the thread competes with the other threads within the program. The system scheduler determines which process will run, the process scheduler determines which thread will run. Some systems allow the developer to specify in what scope the thread will be scheduled. However, in many cases threading is provided by a threads library in which case threads are always scheduled within process scope. Access to the shared resources must be synchronized. If uncontrolled access was allowed race conditions may occur: two threads access the resource at the same time leaving the program in a corrupted state. There exist several techniques to assure the synchronization between threads: semaphores, mutex variables, locks, condition variables, and monitors. For this text we will only use the notion of critical zones. A critical zone is a piece of code that must be executed atomically. This means that only one process can be inside a critical zone at a time. When another process tries to enter a critical zone, it looses the CPU and is put in a waiting line until the critical zone is deserted. A real-time task responds to unpredictable external events in a timely predictable way. After an event occurred an action has to be taken within a predetermined time limit. Missing a deadline is considered a severe software fault. A real-time task must be sure it can acquire the CPU when it needs to, and that it can complete the job within time delay. Since several real-time tasks might be running in the system concurrently, conflicts may arise. Since real-time tasks require the cooperation from the system we will discuss briefly real-time operating systems (RTOS). According to [TM97] for a operating system to be labeled real-time, the following requirements should be met:
The Real-Time Encyclopedia provides a long list of available real-time, mostly embedded systems. The best known public research project on kernel design and real-time systems is the Mach kernel with the real-time extensions (RT-Mach, [TNR90]). The POSIX thread proposal defines an extension for real-time threads [POS96]. The POSIX real-time thread extensions are optional, but several operating systems provide them. Threads and processes are attributed a priority. This priority is used in the scheduling algorithm to determine what thread or process will run next. Priority inversion can occur in the following conditions 1) there are three threads, one with a low, one with a medium, and one with a high priority, 2) the low and the high priority thread share a resource that is protected by a synchronization mechanism. Consider the situation where the low priority thread acquires exclusive access to the shared resource. The medium priority threads wakes up and preempts the low priority thread. When the high priority thread is resumed and tries to acquire access to the resource, it is blocked till the low priority thread releases the shared resource. Since the low priority thread has been suspended by the medium priority thread, the high priority thread is forced to wait for the medium priority thread and could be delayed for an indefinite period of time. The generally accepted solution to the problem is the technique of priority inheritance [SRL87]. Priority inheritance is an attribute of the synchronization mechanism (lock, semaphore, mutex, etc.). Conceptually, it boosts the priority of a low priority thread that acquired a shared resource whenever a high priority thread is waiting for that resource. The priority of the low level thread is set to the priority of the high level thread and can run un-interrupted by medium priority threads till it relinquishes the shared resource. In this way, the high priority thread's worst case blocking time is bounded by the size of the critical zone. In applications where the workload consists of a set of periodic tasks each with fixed length execution times, the rate monotonic scheduling algorithm, developed by Liu & Layland, can guarantee schedulability. The rate monotonic algorithm simply says that the more frequently a task runs (the higher its frequency), the higher its priority should be. If an application naturally is completely periodic or can be made completely periodic, then the developer is in luck because the rate monotonic scheduling algorithm can be employed and a correct assertion can be made about the application meeting its deadlines. Rate monotonic scheduling statically analyses the requirements, which means that the type and number of tasks are known before hand and that their priorities are fixed. The Real-Time Mach kernel uses a time-driven scheduler based on a rate monotonic scheduling paradigm. A thread can be defined for a real-time or a non-real-time activity. A real-time thread can also be defined as a hard or a soft real-time thread, and as periodic or aperiodic based on the nature of its activity. The primary attributes of a periodic thread are its worst case execution time and its period. Aperiodic threads are generally resumed as a result of external events. Their main attributes are the worst case execution time, the worst case interval between two events, and their deadline. The real-time processing of digital video and audio in multimedia applications requires rigid latency and throughput. These applications use several system resources simultaneously such as CPU time, memory, disk and network bandwidth. In addition, the work load of these applications may vary according to user input and new tasks may be added or removed to the system dynamically. In order to provide acceptable output, a resource management is necessary that exceeds the classical scheduling algorithm problem. Furthermore, it should be left to the developer and end user to define the measures of goodness for the performance of the application. Ideally one would provide a range of real-time services from ``guaranteed response time'' to ``best effort'' and allow developers and users to decide whether the extra cost of a more rigid real-time service is worth the perceived benefit. The problem is best expressed in terms of real-time resource allocation and control. A more recent notion in real-time systems is quality of service. Quality of service (QoS) is used in networking, multimedia, distributed, and real-time systems. Applications contending for system resources must satisfy timing, reliability, and security constraints, as well as applications specific quality requirements. The problem is expressed in terms of allocating sufficient resources to different applications in order to satisfy their quality of service requirements. Requirements such as timeliness and reliable data delivery have to be traded of against each other. Applications may content for network bandwidth; real-time applications may need to have simultaneous access to memory cycles or disk bandwidth [Jef92,CSSL97,RLLS97]. The RT-Mach kernel uses a QoS-manager to allocate resources to an application. Each application can operate at any resource allocation point within minimum and maximum thresholds. Different adjustment policies are used to negotiate a particular resource allocation. The RT-Mach QoS server can allow applications to dynamically adjust there resource needs based on system load, user input or application requirements. Quality of service resource allocation supposes that an application may need to satisfy many requirements and require access to many resources. Furthermore, the application requires a minimum resource allocation to perform acceptably. The application utility is defined loosely as the increase in performance when when the application is allocated a new share in the resources. Every application is given a weight, such that the total utility of the system can be measured as the sum of the weighted utilities. Consider, for example, an audio application outputting its samples over the network at a rate of 8kHz. Delivering this quality requires a certain amount of CPU time and network bandwidth. If the application increases its sampling rate to 16kHz the CPU time and bandwidth may double. However, the increase in sound quality might justify the extra claim on the resources: the utility is high. If the application moves the sampling rate to 32kHz, CPU time and bandwidth may double again, but the utility might not be high enough to justify the increase of resource usage. When several applications run concurrently and compete for the resources a negotiation will determine the allocation of the resources between the applications. Quality of service of service not only applies to the usage of the CPU time but includes other system dimensions as well. Before a new task is accepted by the kernel, it must specify its requirements. Once accepted the kernel guarantees that the demand is available.
|
|
|
|
|