


Next: Further developments
Up: Practical results
Previous: Modeling a saxophone
For modeling the time series of the spoken word manna we used a
similar network compared to the saxophone model. Due to the increased
instationarity in the signal we needed an increased number of RBF
units in the network. The best results up to now has been obtained
with a network of 400 hidden units, delay time 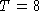 , output
dimension 8 and input dimension 11.
, output
dimension 8 and input dimension 11.
In figure we show the original and the resynthesized
signal. The quality of the model is not as high as in the case of the
saxophone. Nevertheless, the word is quite understandable. From the
figure we see, that the main problems stem from the transitions
between consecutive phonemes. These transitions are rather quick in
time and, therefore, there exists only a small amount of data
describing the dynamics of the transitions. We assume that more
training examples of the same word will cure the problem. However, it
will probably require a well trained speaker to reproduce the dynamics
in speaking the same word twice.
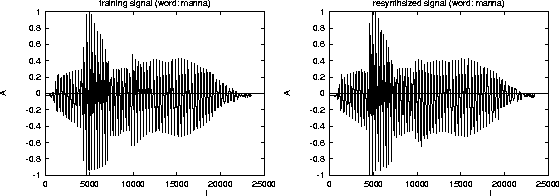
Figure:
Original and synthesized signal of the word manna.
Axel Roebel
Mon Dec 30 16:01:14 MET 1996