Research Interests

- Hidden Markov Models (HMM) for Image and Speech processing
- Speech recognition
- HMM Speech synthesis (HTS)
- Voice Conversion
- Signal and Image Segmentation
- Data fusion
Professional Experiences
Jan 2010 - Jun2011:
Researcher and developer in FEDER AngelStudio project:
IRCAM, Paris, France
- Research on Voice Conversion (Dynamic Model Selection) and development of a system based on GMM modeling of the joint density of source and target acoustic features.
- Implementation of a one-to-many voice conversion system based on a canonical eigenvoice model estimated by SAT for fast Adaptation.
- The aim of VC in this project is to convert the voice of a commercial TTS to the voice of the user using few sentences.
- Research and development of a HMM-based speech synthesis system for French based on HTS with high level syntactical features with N. Obin
Jul 2008 - Jan 2010:
Researcher and developer in ANR Affective Avatars project:
IRCAM, Paris, France
- Research on Voice conversion (reduction of the conditional variance) and development of a Voice conversion system based on GMM modeling of the joint density of source and target acoustic features.
- Research and development of a HMM-based speech synthesis system for French based on HTS including a new excitation model (SVLN) proposed by G. Degottex
Jan 2007 - Jun 2008:
Researcher and developer in ANR VIVOS project:
IRCAM, Paris, France
- Research and development of a segmentation system based on HTK and on the french phonetizer LIAPHON to automatically extract the language structure at different levels (phone, word, phrase, paragraph) and to align it on the speech audio signal.
- Multiple pronunciation are taking into account during the alignment using a constrained phonetic graph build from the text.
- A confidence measure is computed for manual correction.
- The aligned linguistic structure was used in the project by ircamCorpusTools, a corpus manager tool similar to festival, which was developed for Unit selection TTS.
Sep 2005 - Sep 2006:
Teaching assistant for Master students:
Paris XI University, Orsay, France
- Teaching: C language, UNIX, numerical analysis, multimedia (coding), system and network, final projects supervisation.
Sep 2002 - Sep 2005:
Teaching assistant for Master students:
Institut National des telecommunications, Evry, France
- Teaching: Introduction to Statistics, algorithmic and C language, statistical methods in Image processing, final projects supervisation.
Sep 2002 - Dec 2002:
Invited researcher:
Ocean Systems Laboratory, Heriot-Watt University, Edinburgh
- Study and evaluation of SONAR images segmentation algorithm.
Mar 2002 - Sep 2002:
Master Training course in statistical RADAR image segmentation:
TBU Radar Development, THALES Air Defence, Bagneux, France
- Study of statistical radar image segmentation algorithm in the application field of Doppler cartography in order to reduce false alarm in RADAR detection.
Mar 2001 - Sep 2001:
Master Training course in non-linear Mechanics:
UER de M�canique, ENSTA Palaiseau, France
- Analytical and numerical study of the temporal response of a circular plate involving a set of internal resonances in the context of non linear vibration.
Jan 2000 - Mar 2000:
Training course in non-linear Optics:
Photonics and nanostructure laboratory, CNET Bagneux, France
- Simulation of the propagation of a gaussian beam in a non-linear medium (C++)
Education
2002-2006:
Phd in Statistical Signal Processing
Institut National des t�l�communications, Evry, France.
- Title "Triplet Markov chains and Unsupervised signal segmentation"
- Director: Wojciech Pieczynski.
- With honors (mention tr�s honorable)
- Keywords: Hidden Markov Models, Pairwise and triplet Markov chains and trees, Bayesian estimation, Expectation-maximisation, non-stationary process segmentation, centered gaussian process with long memory noise, Dempster-shafer theory, SAR image segmentation.
2001-2002:
DEA OSS: Master Degree in System optimization and safety
Institut National des t�l�communications, Evry, France.
- Major: signal processing and decision theory.
- With honors (mention B)
- Keywords: Logistic, Risk management, System diagnostic, Decision theory in Signal and Image.
2000-2001:
DEA ATIAM: Master Degree in Acoustics, Signal Processing and Computer science applied to Music
Paris VI University/IRCAM, Paris, France
- With honors (mention AB)
- Keywords: Acoustics(general and musical), Audio-numerical signal processing, Computer Science for Music.
2000-2002:
Ing�nieur Telecom INT: Master Degree in Telecommunications (french Grande Ecole)
Institut National des t�l�communications, Evry, France.
- With honors
- Keywords: Signal processing, Computer Science, Probability and statistics, graph optimization, numerical analysis, Information theory, numerical communication, optical communications, Network-TCP/IP, major in statistical image processing during the last year.
1995-2000:
Deug, licence and maitrise de Physique: Bachelor and first year of Master of Science in Physics
Evry-val-d'Essonne University, Evry, France
- With honors (mention AB)
- Keywords: Statistical Physics, Optics, Electromagnetism, Relativity, Quantum Mechanics, Electronics, Numerical Analysis
1995-1997:
Audio engineer diploma
School of Audio Engineering Institute, SAE Paris, France
- a two years degree in sound audio technics
- Keywords: studio and live recording technics, sonorisation, Acoustics, mastering.
1989-1995:
Secondary education
- General education in Sciences
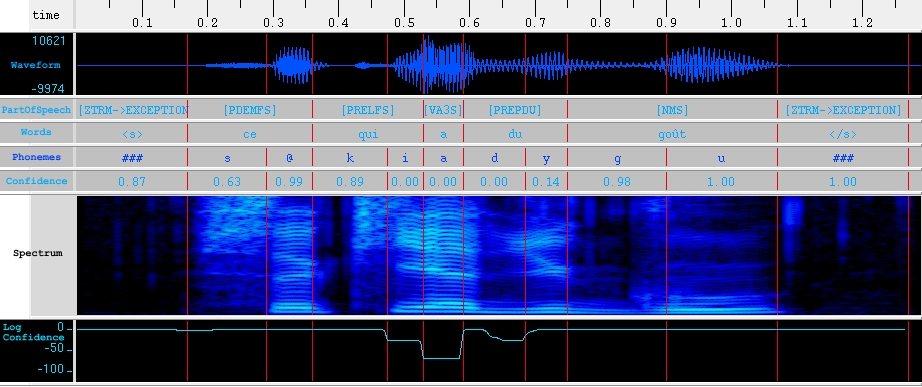
HMM-based Speech Segmentation
ircamAlign
- ircamAlign is a tool for speech segmentation useful to create database for speech synthesis.
- it is based on the HTK toolbox and LLIAPHON french phonetizer
- available for French and English
- audio speech file and its textual transcription are taken as input
- linguistic structure is extracted from the text and aligned on the audio file by considering multi-pronunciation graph to model the dependencies between phonemes.
- if the text transcription is no available, a bi-gram language model is used
- phoneme are modelized by left-right HMM with 7 states.
- Confidence measure are computed at different linguistic level for easier manual correction
- HTS lab features format are directly created to allow the quick creation of new voices.
- Automatic Phoneme Segmentation With Relaxed Textual Constraints,
P. Lanchantin, A. C. Morris X. Rodet and C. Veaux,
LREC'08 Proceedings, Marrakech, Marocco, 2008.
Musical productions using ircamAlign
- ircamAlign is used by composers and it has been used in several musical creations at IRCAM such as:
- Com que voz, Stefano Gervasoni, Thomas Goepfer
- HyperMusic: Prologue, Hector Parra, Thomas Goepfer
- H�xan, la sorcellerie � travers les �ges, Mauro Lanza, Olivier Pasquet
- Cantate �gale pays, G�rard Pesson, S�bastien Roux
- Le p�re, Michael Jarrel, Serge Lemouton
| Hypermusic |
|---|
- some examples here
HMM-Based Speech Synthesis
Baseline system using STRAIGHT for French speech synthesis
- Models were learn on only 200 short phrases = 9 to 10mn of speech.
| HTS | Reference | |
|---|---|---|
| Xavier | ||
| Chungsin | ||
| Carmine | ||
| Cocteau | ||
| Fernando | ||
| Hugues | ||
| Simon | ||
| Thomas | ||
| Tremblay |
- ... and with more data
| HTS | Reference | |
|---|---|---|
| Andr� |
A HMM-Based Speech Synthesis System using a New Glottal Source and Vocal-Tract Separation Methods (with G. Degottex)
- This work introduces a HMM-based speech synthesis system which uses a new method for the separation of vocal-tract and Liljencrants-Fant model plus Noise (SVLN) proposed by G. Degottex.
- The glottal source is separated into two components: a deterministic glottal waveform Liljencrants-Fant model and a modulated Gaussian noise.
- This glottal source is first estimated and then used in the vocal-tract estimation procedure.
- Then, the parameters of the source and the vocal-tract are included into HMM contextual models of phonems.
- The synthesis results were subjectively evaluated here
- A HMM-Based Synthesis System Using a New Glottal Source and Vocal-Tract Separation Method,
P. Lanchantin, G. Degottex and X. Rodet,
ICASSP2010 Proceedings, Dallas, USA, 2010.
| Pair | Pulse | STRAIGHT | SVLN |
| 2 | |||
| 4 | |||
| 6 | |||
| 8 | |||
| 11 |
Transformation examples
- SVLN is promising for voice transformation in synthesis of expressive speech since it allows an independent control of vocal-tract and glottal-source properties.
| F0 scale | VTF scale | Rd scale | Audio (HTS) | |
|---|---|---|---|---|
| 1 | 1 | 1 | Original voice | |
| 0.6 | 1 | 1 | ||
| 0.6 | 0.85 | 1 | ||
| 0.6 | 0.85 | 0.5 | Baryton voice | |
| 2.5 | 1 | 1 | ||
| 2.5 | 1.7 | 1 | ||
| 2.5 | 1.7 | 3 | Little girl voice |
Toward Improved HMM-based Speech Synthesis using High-Level Syntactical Features (with N. Obin)
- A major drawback of current Hidden Markov Model-based speech synthesis is the monotony of the generated speech which is closely related to the monotony of the generated prosody.
- This work presents a linguistic-oriented approaches in which high level linguistic features are extracted from text in order to improve prosody modeling.
- A linguistic processing chain based on linguistic preprocessing, morpho-syntactical labeling, and syntactical parsing is used to extract high-level syntactical features from an input text.
- Rich linguistic features are then introduces into a HMM-based speech synthesis system to model prosodic variations (f0, duration, and spectral variations).
- Subjective evaluation reveals that the proposed approach significantly improve speech synthesis compared to a baseline model, even if such improvment depends of the observed linguistic phenomenon.
- Toward Improved HMM-Based Speech Synthesis Using High-Level Syntactical Features,
N. Obin, P. Lanchantin, M. Avanzi, A. Lacheret-Dujour and X. Rodet,
Speech Prosody 2010 Proceedings, Chicago, USA, 2010.
| example 1 | |||
|---|---|---|---|
| example 2 |
Speaking Style Modeling of Various Discourse Genres in HMM-Based Speech Synthesis (with N. Obin)
- This work presents an approach for modeling speaking style of various discourse genres in speech synthesis.
- The proposed approach is based on phonological and acoustic average discourse genre - dependent speaking style parametric models.
- The phonological module models the average abstract prosodic structure of a specific discourse genre.
- The acoustic module jointly models average speaking style voice and prosodic cues of a given discourse genre.
- Discourse genre - dependent speaking style models have been estimated for 4 discourses genres and evaluated on a speaking style prosodic identification perceptual experiment.
- A comparison with speaking style identification on real speech is discussed and reveals consistent performance of the proposed approach.
- Speaking Style Modeling of Various Discourse Genres in HMM-Based Speech Synthesis,
N. Obin, P. Lanchantin, A. Lacheret-Dujour and X. Rodet,
ICASSP 2011, Prague, Czech Republic, May 2011, Submitted
| Samples | ||||
|---|---|---|---|---|
| Prosodical stereotype | ||||
| HTS |
Voice Conversion
Dynamic Model Selection for spectral Voice Conversion
- Statistical methods for voice conversion are usually based on a single model selected in order to represent a tradeoff between goodness of fit and complexity.
- In this work we assumed that the best model may change over time, depending on the source acoustic features.
- We present a new method for spectral voice conversion called Dynamic Model Selection (DMS), in which a set of potential best models with increasing complexity - including mixture of Gaussian and probabilistic principal component analyzers - are considered during the conversion of a source speech signal into a target speech signal.
- This set is built during the learning phase, according to the Bayes information criterion. During the conversion, the best model is dynamically selected among the models in the set, according to the acoustical features of each frame.
- Subjective tests show that the method improves the conversion in terms of proximity to the target and quality.
- Dynamic Model Selection for Spectral Voice Conversion,
P. Lanchantin and X. Rodet,
''Interspeech 2010 Proceedings, Makuhari, Japan, Sept 2010.
VC from real source voice
- Target Reference Samples
| # | Fernando | Tremblay | Gilles |
| 004 |
- Converted source envelope
| # | Xavier | Fernando | Tremblay | Gilles |
| 001 | ||||
| 082 | ||||
| 088 | ||||
| 099 |
VC from a commercial TTS source voice
- Target Reference Samples
| # | BO |
| 012 | |
| 013 |
- Converted source envelope
| # | Ryan | BO |
| 001 | ||
| 003 | ||
| 011 | ||
| 049 | ||
| 071 | ||
| 078 | ||
| 082 | ||
| 171 |